
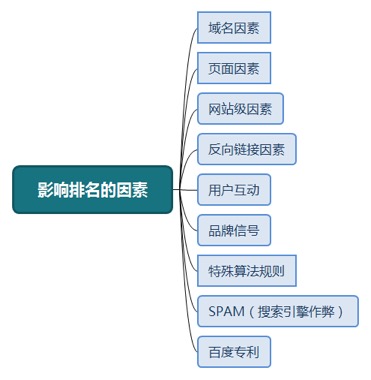
影响排名的因素
影响排名的因素
1.2.1. 域名未被投诉或者处罚............................................................................. 61
1.2.1.1. 域名注册申请者提供域名持有者真实、准确、完整的身份信息等域名注册信息。 61
1.2.1.4. 违反广告法,违禁词.......................................................................... 61
1.2.2. 域名未被判断为不安全域名..................................................................... 61
1.2.3.1. 如果某人被识别为垃圾邮件发送者,那Google会仔细检查该人拥有的网站是否有意义。 62
1.4.1. 如果域名所有权几经更迭,那Google可能会重置网站的历史记录,以前域名的反向链接价值会被丢掉。 63
1.5.1. 如果域名和关键词完全一致,如果网站质量很高,这依然是优势。否则反而更容易被识别惩罚。 63
1.6.1. 不像过去有助于提升排名,但域名中的关键词仍然作为相关性的一种信号。 64
1.7. 域名开头包含目标关键词................................................................................ 64
1.7.1. 在域名开头包含目标关键词,相对于不含关键词或尾部包含关键词的域名有优势。 64
2.1.1.1. 标题中包含关键词.............................................................................. 67
2.1.1.2. Title中的潜在索引关键词.................................................................. 67
2.1.1.2.1.1. https://wenku.baidu.com/view/64118259804d2b160b4ec03a.html 68
2.1.2.1. Description中的包含关键词.............................................................. 68
2.1.2.2. Description中的潜在索引关键词...................................................... 68
2.1.2.2.1. 与网页内容一样,Meta标签中的潜在索引关键词(LSI)有助于Google辨别同义词,也可以作为页面相关性信号。 69
2.2.1.1. H1标签中出现关键词........................................................................ 69
2.2.1.2. H2/H3标签中出现关键词.................................................................. 70
2.2.1.2.1. 将关键词显示在H2或H3标签的副标题中是另一个弱相关信号。 70
2.2.2.1. 页面中出现关键词.............................................................................. 70
2.2.2.1.1. 页面中有关键词比其他任何相关性都更有说服力。................ 71
2.2.2.2.1. 虽然不像以前那么重要,但依然会被Google用来确定网页主题。但关键词密度过大会有反作用。 71
2.2.2.3.1. 关键词出现在页面前100个字中似乎是一个重要的相关信号。 71
2.2.2.5. 内容中的潜在语义索引关键词(LSI)................................................... 72
2.2.3.2.1.1. 同一网站上的相同内容(可能稍作修改)可能会对网站搜索引擎的收录和排名有负面影响。 74
2.2.3.2.1.2. 页面上的内容是否是原创?如果是从Google索引页面中采集或复制的,它不会获得和原始内容一样的排名。 74
2.2.3.2.2. 段落相邻语义相关性.................................................................... 74
2.2.3.2.3. 对话内容连贯性............................................................................ 75
2.2.3.2.4.1. 正如Backlinko读者Jared Carrizales所指出,Google可能会区分“高质量”和“有用的”内容的不同。 75
2.2.3.2.5. 有用的补充内容............................................................................ 75
2.2.3.2.6. 无序和和有序列表........................................................................ 75
2.2.3.2.6.1. 有序列表有助于为读者分解内容,用户体验会更好。Google可能更喜欢使用列表的内容。 75
2.2.3.2.7. 内容可阅读等级............................................................................ 75
2.2.3.2.8.1. 页面出现在什么类别是一个相关信号,如果页面和类别不相关,则很难获得好的排名。(信息要发布到正确的分类) 76
2.2.3.2.9.1. 图像,视频和其他多媒体元素可以作为内容质量信号。. 76
2.2.3.2.10. 参考资料和来源.......................................................................... 76
2.2.3.2.11. 用户友好的布局.......................................................................... 77
2.2.3.2.11.1. 这里再次引用Google质量指南文件:“高质量的页面布局会让页面主体部分很容易被用户看到”。 77
2.2.3.2.12. 人工干预编辑.............................................................................. 77
2.2.3.2.12.1. 人工编辑影响搜索引擎结果页(SERP)................................. 77
2.2.3.3.1.1. 虽然搜索引擎喜欢新鲜的内容,但是定期更新的旧页面可能会超过新页面。 78
2.2.3.3.2. Google Caffeine算法对时间敏感的搜索很重视,表现就是搜索结果会显示内容更新时间。 78
2.2.3.4.1. 编辑和更新也是一个页面新鲜度因素。添加或删除整个段落才算重要更新,不能只是调换一些词的顺序。 78
2.2.3.4.2. 页面历史更新频次........................................................................ 78
2.2.3.4.2.1. 页面多久更新?每天、每周、每隔5年?页面更新频率在提升页面新鲜度中起到重要作用。 79
2.3.1.1. 如果其他一切条件相同,权重高的域名页面排名更好。.............. 79
2.3.2.1. 虽然并不完全相关,但是一般来说,页面有更高的PR值,排名会比PR值低的好。(Google现在已经没有PR值了) 80
2.3.3. 其他关键字的排名页面数量..................................................................... 80
2.3.3.1. 如果页面获得了其他关键字的排名,那么这个词的排名权重可能会提升。 80
2.3.4.1. 2011年12月的Google更新降低了停靠域名的搜索可见性。..... 80
2.4.2.1. 无论Google还是Bing都使用页面加载速度作为一个排名因素。搜索引擎蜘蛛会根据页面代码和文件大小估算网站速度。 81
2.4.3. Chrome浏览器访问速度........................................................................... 81
2.4.3.1. Google可能会使用Chrome的用户数据来识别与HTML代码无关的页面加载速度情况。 81
2.5.1.1.1. 链接指向权重网站有助于向Google发送信任信号。............... 82
2.5.1.4.1. 有些网页有太多导出链接,会干扰和分散主要内容。............ 83
2.5.2.1. 指向页面的内部链接的数量.............................................................. 83
2.5.2.1.1. 网站内链数量表明它相对于其他页面的重要性,越多越重要。 83
2.5.2.2. 指向页面的内部链接的质量.............................................................. 83
2.5.2.2.1. 网站里高权重(PR)页面的内链效果比低权重(或无权重)的效果好很多。 84
2.5.4.1. 页面太多死链是网站被遗弃或没人维护的特征,Google会使用死链来评估网站首页质量。 84
2.6.1.1. 目录层级越浅,越靠近根域名,可以增加URL权重。................. 85
2.6.2.1. URL中出现的关键词是一个重要的相关信号。.............................. 85
2.6.3.1. Google会自动识别URL字符串中的目录和分类,可以识别出页面主题。 86
2.6.4.1. URL过长可能会影响搜索排名.......................................................... 86
2.7.1. HTML错误和W3C验证............................................................................. 87
2.7.2.1. 合理使用 rel="canonical"标记,会防止Google误判网站内容重复而惩罚。 87
2.7.3.1. 图片的文件名、Alt文本、Title、Description和Caption都是重要的页面相关性指标。 88
2.7.3.2. Alt标签(用于图像链接)...................................................................... 88
2.7.3.2.1. Alt文本可以说是图像的”锚文本“。........................................... 88
2.7.4.1. Sitemap.xml文件中指定的页面优先级可能会影响排名。............ 88
2.7.5.1. 正确的语法和拼写是一个页面质量信号。...................................... 89
3.1.1. 域名获得多少来自种子站点(搜索引擎极度青睐的抓取起始站点)的链接是一个非常重要的排名因素。TrustRank站说明) 91
3.2.1. 内容可以提供价值和独特的见解............................................................. 91
3.2.2.1. 网站的更新频次,尤其是添加新内容时。这是一个很好的提升网站新鲜度的信号。 91
3.2.3.1. 网站页面数对权重略有影响。.......................................................... 92
3.2.4.1. Google质量文件指出,他们更喜欢具有“适当联系信息”的网站。如果网站的联系信息和whois信息一致,可能会有奖励。 92
3.2.5. 服务条款和隐私页面................................................................................. 92
3.2.5.1. 这两个页面有助于告诉Google你的网站是值得信赖的。............ 92
3.2.6.1. 落地页时间因子是百度搜索判断网站收录、展示、排序结果的重要参考依据。 92
3.2.6.1.1. 首页|栏目-最新时间..................................................................... 93
3.2.6.1.2. 专题|内容-发布时间..................................................................... 93
3.3.2. 结构要点:将同类型和主题的页面放在一起;分离不相关的页面;加强每个目录的着陆页。 93
3.3.3. 重复的Meta标签内容.............................................................................. 93
3.3.3.1. 网站页面使用重复一样的Meta keywords和Description可能会降低你的所有页面可见性。 94
3.3.4.1. 拥有面包屑导航是用户体验良好的网站结构风格,可以帮助用户(和搜索引擎)知道他们在网站上的位置。 94
3.4.1. 站点地图有助于搜索引擎更轻松、更彻底地抓取和索引你的页面,提高页面可见性(搜索排名)。 94
3.5.1. 网站经常维护或宕机可能会影响排名(如果没有及时修复,甚至可能导致减少索引量) 95
3.6.1. 服务器位置可能会影响网站在不同地区的排名,对于地域相关的搜索特别重要。 95
3.7.1. 已经确认Google百度会索引SSL证书,并使用HTTPS作为排名信号。 95
3.8.1. 用户停留时间、访问深度、跳出率......................................................... 96
3.9. 站长统计代码 站长分析代码......................................................................... 96
3.9.1. 百度统计、百度站长工具、360站长、神马站长、Sogou站长、谷歌分析 96
4.1.1.1. 老域名的反向链接可能比新域名作用更大。.................................. 99
4.1.2. 独立C类IP的链接数................................................................................ 99
4.1.2.1. 来自不同C类IP(Class-C)数量越多,说明链接广泛性越好............ 99
4.1.3. 来自.edu或.gov类域名链接..................................................................... 99
4.1.4.1. 同等页面权重下,域名权重越高越好(PR3站点的PR2页面权重小于PR8网站的PR2页面)。 100
4.1.5.1. 来自类似主题的利基站点(垂直网站)链接比来自完全不相关网站的链接更强大。有效的SEO策略依然着重于获得相关链接。 100
4.1.6.1. Hilltop算法指出,与页面内容紧密相关的链接权重比不相关页面链接权重更高。(百度专利) 100
4.1.7.1. 反向链接的页面权重(PageRank)是非常重要的排名因素。(百度专利) 101
4.1.7.2. 导入链接的用户点击 链接流量(百度专利)............................... 101
4.1.8. 来自竞争对手的链接............................................................................... 101
4.1.8.1. 如果你能获得关键词搜索结果中其他网站的反向链接,则对于关键词排名特别有价值。 101
4.1.9. 来自网站首页的链接............................................................................... 101
4.1.9.1. 来自网站首页的链接权重比内页的要高很多。............................ 101
4.1.10. 链接类型的多样性............................................................................... 101
4.1.11. 社会化网站引用页面........................................................................... 102
4.1.11.1. 被社会化(设计)网站引用可能会影响链接的价值,被引用的越多越好。 102
4.1.12.1. Aaron Wall声称,从专业的相关主题页面获取的的链接会给予更高的权重。 102
4.1.13.1. 从公认的行业权威网站获得的链接比小的专题网站获得好处多。 103
4.1.14. 维基百科的引用链接........................................................................... 103
4.1.15. 反向链接添加时间............................................................................... 103
4.1.15.1. 根据Google专利,以前添加的链接比新加的反向链接具有更多的权重。 更新时间(百度专利) 103
4.1.16. 真实网站链接与垃圾博客链接........................................................... 103
4.1.16.1. Google给“真实网站”的链接权重比垃圾博客链接高。Google可能会使用品牌和用户互动信号来区分两者。 104
4.1.17.1. 拥有“自然链接”的网站将排名高,而且排名更稳定持久。........ 104
4.1.18.1. Google指出“过度链接交换”是一种作弊,需要避免。............... 104
4.1.19. 链接网站的可信度(TrustRank)............................................................. 104
4.1.19.1. 网站的可信度也可以传递,如果很多可信度高的网站指向到你网站,对排名有好处。 104
4.1.20. 页面的出站链接数量........................................................................... 104
4.1.20.1. 页面的PageRank是有限的,导出链接多的页面比导出少的效果差。 105
4.1.21.1. 由于大量作弊,Google可能会大大降低论坛中链接的权重。... 105
4.1.22.1. Matt Cutts已经确认,全站链接被“压缩”识别为单个链接。..... 105
4.1.24. 用户生成的内容链接........................................................................... 106
4.1.26.1. 像“合作伙伴”、“赞助商链接”这样的词语可能会降低其附近链接的价值。 107
4.1.27. 来自301跳转的链接........................................................................... 107
4.1.27.1. 经过301重定向的链接与直接链接相比可能会损失一点点权重,然而Google的Matt Cutts说:301链接类似于直接链接。 107
4.1.28. 引荐域的国家/地区.............................................................................. 107
4.1.28.1. 从国家/地区的顶级域名(.de,.cn,.http://co.uk)获取链接可能会帮助网站在该国家排名更好。 107
4.1.29.1. 许多人认为,Google会给被http://DMOZ.com收录的网站更多的信任和权重。 108
4.1.30. 过多301重定向页面........................................................................... 108
4.1.30.1. 根据Google网站管理员帮助视频,过多301重定向链接会稀释部分(甚至全部)PR 。 108
4.1.31. 来自垃圾网站的链接........................................................................... 108
4.1.31.1. 来自垃圾网站的链接可能会伤害网站排名。............................... 108
4.2.1.1. Google对页面标题中包含对应关键字的链接给予更多权重(“专家链接到专家”,类似于专家间的互相推荐,可信度更高)。 109
4.2.2.1. 支持Schema微格式的页面可以在Google的搜索结果中出现,从而直接提升搜索结果页的点击率这是不争的事实。 109
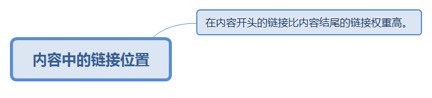
4.2.3.1. 内容中的链接位置............................................................................ 110
4.2.3.1.1. 在内容开头的链接比内容结尾的链接权重高。...................... 110
4.2.3.2. 页面中的链接位置............................................................................ 110
4.2.3.2.1. 通常,在页面主体内容中添加的链接比页面底部或侧边栏中的链接权重更高。 110
4.2.4. 链接周围文字代表的情绪....................................................................... 110
4.2.4.1. Google可能已经可以根据链接周围文本识别出情绪,分析出链接是推荐还是负面批评引用。 111
4.2.5.1. 在反向链接周围出现的文本有助于告诉Google你的页面主题。 111
4.2.6.1. 1000字帖子中的链接比25个字帖中的链接更有价值。............ 111
4.2.7. 链接页面的内容质量............................................................................... 111
4.2.7.1. 拼写错误多,语句不通内容里的链接价值不如专业包含多媒体内容里的链接。 111
4.3.1.1. 链接标题(当悬停在链接上时出现的文本)也用作弱相关信号。. 112
4.3.3.1. 内部链接锚文本是另一个相关性的信号,虽然可能与反向链接的锚文本权重不同。 113
4.4.2.1. 链接页面的总数很重要, 即使部分都来自同一个域名,这也对排名有帮助。 114
4.4.3.1.1. 链接增加速度(反向链接增加速度快于减少速度)的网站通常会得到搜索结果排名提升。 114
4.4.3.2.1. 链接减少速度(反向链接减少速度快于增加速度))可以显著降低排名,因为它是流行度下降的信号。 115
5.1. 搜索关键词的页面点击率............................................................................. 116
5.1.1. 搜索结果中点击率高的页面可能会获得该特定关键字的排名提升。百度算法也是这样,这就是各种“网页快排”技术的理论基础。 116
5.2. 所有搜索关键词的页面点击率..................................................................... 116
5.5.1. Google还可以知道用户是否再次访问这个页面或网站,Google可能会提高再次访问多的网站排名。 117
5.6.1. 拥有大量评论的页面是交互好、内容质量高的表现。....................... 117
5.8.1. Google熊猫2.0算法仍然用这个数据作为质量信号。....................... 118
5.9.1. 被用户加入浏览器书签的页面可能会提升排名。............................... 119
6.1.1. 品牌名锚文本是一个简单而强大的品牌信号。................................... 120
6.2.1. 品牌和品牌组合词搜索的越多,搜索引擎对你网站的认可也就越多。 120
6.3.1. 真正的大品牌能在新闻中找到很多相关信息。事实上,一些品牌甚至在搜索结果首页有新闻列表。 121
6.4.1.1. 合法正常社交媒体账户.................................................................... 122
6.4.1.1.1. 同样拥有10,000关注者,跟关注者互动多的比少的好很多。 122
6.4.1.3.1. 粉丝多,创建早,影响力大的Twitter号比来自新的、低影响力的帐户的推文链接更有影响力。 123
6.4.1.4.1. 虽然Google看不到大多数Facebook帐户,但有他们可能把Facebook Like数量当作弱排名信号。 123
6.4.1.5.1. Facebook分享与反向链接更相似,应该比Facebook Like数量更有影响力。 124
6.4.1.6. Facebook用户权重........................................................................... 124
6.4.1.6.1. 粉丝多、影响大的Facebook账号上的分享和Like数据,搜索引擎会传达更多权重。 124
6.4.1.7.1. Pinterest是一个很流行的社会化媒体网站,拥有大量的公开资料。Google可能用Pinterest的数据作为排名信号。 124
6.4.1.8.1. Google可能会用Reddit,Stumbleupon和Digg等网站的分享作为另一种排名信号。 125
6.4.1.9.1. 虽然Matt Cutts明确说过Google+对排名“没有直接影响 ”,但很难相信他们会忽略自己的社交网络。 125
6.4.1.10.1. 从逻辑上说,Google会更看重权威账号的权重。................ 125
6.4.1.12. 社会信号相关性............................................................................... 126
6.4.1.12.1. Google可能会用分享的内容和链接周围文字判断相关性。 126
6.4.1.13. 网站Facebook主页和Like.............................................................. 126
6.4.1.13.1. 品牌往往拥有Facebook主页,而且Like数很多。.............. 126
6.4.1.14.1. 大多数真实企业在Linkedin上都有页面。............................ 127
6.4.1.15.1. Rand Fishkin认为让员工们开通LinkedIn帐号,并在资料中填写公司名称有助于增强公司品牌信号。 127
6.4.1.16. 网站Twitter账户和关注者............................................................. 127
6.4.1.16.1. 知名流行品牌的Twitter账户往往有大量关注者。.............. 127
6.4.1.17.1. 在Google+ 本地名录中找到意味着网站有实体办公室,Google用此来确定你的网站是否为一个大品牌。 128
6.4.1.19. 网站是否有纳税信息....................................................................... 128
6.4.1.19.1. http://Moz.com指出Google可能看一个网站是否提供税务信息。 128
6.4.2.1.1. 整站在社交媒体的活跃度信号可能会增加整站的权重,这会有效提高网页的搜索可见性。 129
7.1.1.1.1. 上线时间:2017年7月4号公布............................................. 132
7.1.1.1.1.1. 打击对象:严厉打击以恶劣采集为内容主要来源的网站。 132
7.1.1.1.1.1.1. https://ziyuan.baidu.com/wiki/1050............................. 132
7.1.1.2. 百度飓风算法2.0.............................................................................. 132
7.1.1.2.1. 上线时间:2018年9月13号公布........................................... 132
7.1.1.2.1.1.1. https://ziyuan.baidu.com/wiki/2585............................. 133
7.1.1.3. 百度飓风算法3.0.............................................................................. 133
7.1.1.3.1. 上线时间:2019年8月22号公布........................................... 134
7.1.1.3.1.1. 打击对象:针对跨领域采集以及站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序等内容。 134
7.1.1.3.1.1.1. https://ziyuan.baidu.com/college/articleinfo?id=2850. 134
7.1.1.4.1. 上线时间:2016年11月21号公布......................................... 134
7.1.1.4.1.1. 重点打击买卖软文的网站,包括新闻源和其他一些高权重网站,违规网站会受到降低权重排名。 135
7.1.1.4.1.1.1. https://ziyuan.baidu.com/wiki/933............................... 135
7.1.1.5.1. 上线时间:2018年5月31号公布........................................... 135
7.1.1.5.1.1. 旨在倡导资源方重视网站落地页时间规范。落地页时间因子是百度搜索判断网站收录、展示、排序结果的重要参考依据。 135
7.1.1.5.1.1.1. https://ziyuan.baidu.com/wiki/2245............................. 136
7.1.1.6. 百度搜索下载站质量规范................................................................ 136
7.1.1.6.1. 上线时间:2018年10月11号公布......................................... 136
7.1.1.6.1.1. https://ziyuan.baidu.com/college/articleinfo?id=2653........ 136
7.1.1.7. 百度搜索落地页时间因子规范........................................................ 136
7.1.1.7.1. 上线时间:2018年5月7号公布............................................. 136
7.1.1.7.1.1. https://ziyuan.baidu.com/college/articleinfo?id=2210........ 137
7.1.2.1.1. 上线时间:2017年9月14号公布,9月底上线.................... 138
7.1.2.1.1.1. 打击对象:提过页面标题作弊,欺骗用户获得点击的行为。 138
7.1.2.1.1.1.1. https://ziyuan.baidu.com/college/articleinfo?id=1659. 138
7.1.2.2.1. 上线时间:2017年10月19号公布,10月初已上线............ 138
7.1.2.2.1.1. 主要影响:移动页面首屏加载时间将影响搜索排名....... 138
7.1.2.2.1.1.1. https://ziyuan.baidu.com/college/articleinfo?id=1591. 138
7.1.2.3. 百度清风算法2.0.............................................................................. 139
7.1.2.3.1. 上线时间:2018年4月19号公布........................................... 139
7.1.2.3.1.1. 打击对象:严厉打击欺骗下载........................................... 139
7.1.2.3.1.1.1. 1.实际下载的资源与需求不符..................................... 139
7.1.2.3.1.1.2. 2. 提供了下载链接、实际站点无下载资源................ 139
https://ziyuan.baidu.com/wiki/2160(1.实际下载的资源与需求不符, 2. 提供了下载链接、实际站点无下载资源) 139
7.1.2.4.1. 上线时间: 2018年 6 月 28号公布.......................................... 140
7.1.2.4.1.1.1. https://ziyuan.baidu.com/college/articleinfo?id=2389. 140
7.1.2.5. 百度清风算法3.0.............................................................................. 140
7.1.2.5.1. 上线时间:2018年10月16号公布......................................... 141
7.1.2.5.1.1. 打击对象:对下载站的标题作弊、欺骗下载、捆绑下载等问题进行全面审查 141
7.1.2.5.1.1.1. https://ziyuan.baidu.com/wiki/2664............................. 141
7.1.2.6. 百度搜索网页标题规范.................................................................... 141
7.1.2.6.1. 上线时间:2018年10月15号................................................. 141
7.1.2.6.1.1. https://ziyuan.baidu.com/college/articleinfo?id=2728........ 141
7.1.2.7. 严厉打击虚假诈骗等违法违规信息的公告.................................... 141
7.1.2.7.1. 上线时间:2019年2月27号公布........................................... 142
7.1.2.7.1.1. 打击对象:严厉打击电信网络中的虚假诈骗、违法交易、黄赌毒等违法违规信息。 142
7.1.2.7.1.1.1. https://ziyuan.baidu.com/wiki/2770............................. 142
7.1.2.8.1. 上线时间:2019年5月22号公布........................................... 142
7.1.2.8.1.1. 打击对象:利用翻页键诱导用户的行为........................... 143
7.1.2.8.1.1.1. https://ziyuan.baidu.com/wiki/2789............................. 143
7.1.3.1.1. 上线时间:2013年2月19号公布........................................... 144
7.1.3.1.1.1. 打击对象:买卖链接的行为,包括超链中介、出卖链接的网站、购买链接的网站。 144
7.1.3.1.1.1.1. https://ziyuan.baidu.com/wiki/142............................... 144
7.1.3.2. 百度绿萝算法2.0.............................................................................. 144
7.1.3.2.1. 上线时间:2013年5月17号公布........................................... 144
7.1.3.2.1.1. 打击对象:软文中的外链及惩罚发软文的站点。........... 144
7.1.3.2.1.1.1. https://ziyuan.baidu.com/college/articleinfo?id=30..... 145
7.1.3.3.1. 上线时间:2017年11月20号公布,2017年11月底上线.. 145
7.1.3.3.1.1. 打击对象:严厉打击通过刷点击,提升网站搜索排序的作弊行为;以此保证搜索用户体验,促进搜索内容生态良性发展。 145
7.1.3.3.1.1.1. https://ziyuan.baidu.com/wiki/1686............................. 145
7.1.3.4. 百度惊雷算法2.0.............................................................................. 145
7.1.3.4.1. 上线时间:2018年5月23号公布........................................... 145
7.1.3.4.1.1.1. https://ziyuan.baidu.com/wiki/2235............................. 146
7.1.4.1.1. 上线时间:2016年8月10号公布........................................... 147
7.1.4.1.1.1. 重点打击网站JS代码恶意套取用户隐私信息,如套电手机号、QQ号等行为,网站清理掉违规JS可解除百度惩罚。 147
7.1.4.1.1.1.1. https://ziyuan.baidu.com/wiki/883............................... 148
7.1.4.2.1. 上线时间:2017年2月23号公布........................................... 148
7.1.4.2.1.1. 打击对象:百度移动搜索页面劫持。............................... 148
7.1.4.2.1.1.1. https://ziyuan.baidu.com/wiki/968............................... 148
7.1.4.3. 百度蜘蛛升级https抓取................................................................. 148
7.1.4.3.1. 上线时间:2017年8月30号公布,8月期间已上线............ 149
7.1.4.3.1.1. 主要影响:升级了对HTTPS数据的抓取力度,HTTPS数据将更快被Spider抓取到。 149
7.1.4.4. HTTPS改造全解析............................................................................ 149
7.1.4.4.1. 上线时间:2018年2月5号公布............................................. 149
7.1.4.4.1.1. https://zy.baidu.com/actxzh/https?isResponsible=1........... 149
7.1.4.5. 网站被黑操作指南............................................................................ 149
7.1.4.5.1. 上线时间:2018年3月21号公布........................................... 150
7.1.4.5.1.1. https://ziyuan.baidu.com/college/articleinfo?id=1949........ 150
7.1.4.6. 百度烽火算法2.0.............................................................................. 150
7.1.4.6.1. 上线时间:2018年5月17号公布........................................... 150
7.1.4.6.1.1.1. https://ziyuan.baidu.com/wiki/2222............................. 151
7.1.4.7. 百度烽火算法3.0.............................................................................. 151
7.1.4.7.1. 上线时间:2019年3月14号公布........................................... 151
7.1.4.7.1.1.1. https://ziyuan.baidu.com/wiki/2778............................. 152
7.1.5.1.1. 上线时间:2013年5月17号................................................... 153
7.1.5.1.1.1. 打击对象:大量妨碍用户正常浏览的恶劣广告的页面、低质量内容页面 154
7.1.5.1.1.1.1. https://ziyuan.baidu.com/wiki/174............................... 154
7.1.5.2. 百度冰桶算法1.0.............................................................................. 154
7.1.5.2.1. 上线时间:2014年8月22号................................................... 154
7.1.5.2.1.1. 打击对象:移动端影响用户体验的落地页。................... 154
7.1.5.2.1.1.1. https://ziyuan.baidu.com/wiki/313............................... 155
7.1.5.3. 百度冰桶算法2.0.............................................................................. 155
7.1.5.3.1. 上线时间:2014 年 11 月 18 日................................................. 155
7.1.5.3.1.1. 打击对象:全屏下载、在狭小的手机页面布设大面积广告遮挡主体内容、强制用户登录才可以使用等。 155
7.1.5.3.1.1.1. https://ziyuan.baidu.com/wiki/697............................... 155
7.1.5.4. 百度冰桶算法3.0.............................................................................. 155
7.1.5.4.1. 上线时间:2016年7月7号公布,7月15号上线................ 156
7.1.5.4.1.1. 打击对象:打断用户完整搜索路径的行为。................... 156
7.1.5.4.1.1.1. https://ziyuan.baidu.com/wiki/870............................... 156
7.1.5.5. 百度冰桶算法4.0.............................................................................. 156
7.1.5.5.1. 上线时间:2016年9月19号公布........................................... 156
7.1.5.5.1.1. 打击对象:广告过多、影响用户体验的移动页面。....... 157
7.1.5.5.1.1.1. https://ziyuan.baidu.com/wiki/900............................... 157
7.1.5.6. 百度冰桶算法4.5.............................................................................. 157
7.1.5.6.1. 上线时间:2016年10月26号公布......................................... 157
7.1.5.6.1.1. 打击对象:发布恶劣诱导类广告的页面。....................... 157
7.1.5.6.1.1.1. https://ziyuan.baidu.com/wiki/911............................... 158
7.1.5.7. 百度冰桶算法5.0.............................................................................. 158
7.1.5.7.1. 上线时间:2018年11月12号公布......................................... 158
7.1.5.7.1.1. 保障搜索用户体验............................................................... 158
7.1.5.7.1.1.1. https://ziyuan.baidu.com/wiki/2723............................. 158
7.1.5.8. 百度移动搜索落地页体验白皮书4.0.............................................. 158
7.1.5.8.1. 上线时间:2018年8月15号公布........................................... 159
7.1.5.8.1.1. https://ziyuan.baidu.com/college/documentinfo?id=2492. 159
7.1.5.9. 严厉打击色情低俗广告内容............................................................ 159
7.1.5.9.1. 上线时间:2019年1月23号公布........................................... 159
7.1.5.9.1.1. https://ziyuan.baidu.com/wiki/2758.................................... 159
7.1.5.10. 严格控制搜索中的权限问题........................................................... 159
7.1.5.10.1. 上线时间:2019年4月18号公布......................................... 159
7.1.5.10.1.1. https://ziyuan.baidu.com/wiki/2785.................................. 160
7.2.1. 马加比更新(Maccabees Update)........................................................... 161
7.2.1.1. 上线时间:2017年12月12号...................................................... 162
7.2.2. 移动优先索引(Mobile First Index)......................................................... 162
7.2.2.1. 上线时间:2017年10月中旬........................................................ 162
7.2.3.1. 上线时间:2017年4月25号........................................................ 163
7.2.3.1.1. 受影响网站:虚假新闻内容,如编造的假新闻,极度偏见、煽动仇恨,谣言等。参见以前写的关于猫头鹰算法的帖子。 163
7.2.4. 弗雷德更新(Fred Update)...................................................................... 163
7.2.4.1. 上线时间:2017年3月8号.......................................................... 163
7.2.5. 移动页面干扰插页惩罚算法(Intrusive Interstitial Penalty).................. 164
7.2.5.1. 上线时间:2017年1月10号........................................................ 164
7.2.6. 企鹅更新4.0(Penguin 4.0)..................................................................... 164
7.2.6.1. 上线时间:2016年9月23号,10月12号左右完成................. 164
7.2.7. 移动友好算法2(Mobile Friendly Algorithm 2)...................................... 165
7.2.7.1. 上线时间:2016年4月21号........................................................ 165
7.2.7.1.1. 受影响网站:2015年4月21号第一次Google移动友好算法的一次更新,使更多移动友好页面能被用户看到。 165
7.2.8. APP安装插页广告惩罚(APP Install Interstitial Penalty)....................... 165
7.2.8.1. 上线时间:2015年11月2号........................................................ 165
7.2.9.1. 上线时间:2015年10月26号...................................................... 166
7.2.10. 被黑网站删除算法(Hacked Spam)......................................................... 166
7.2.10.1. 上线时间:2015年10月................................................................ 167
7.2.11. 熊猫算法4.2(Panda Update 4.2)........................................................... 167
7.2.11.1. 上线时间:2015年7月18号........................................................ 167
7.2.12.1. 上线时间:2015年5月1号左右.................................................. 168
7.2.13. 移动友好算法(Mobile Friendly Algorithm)............................................ 168
7.2.13.1. 上线时间:2015年4月21号........................................................ 168
7.2.14.1. 上线时间:2014年8月7号.......................................................... 169
7.2.15.1. 上线时间:2014年7月24号........................................................ 170
7.2.16. 蜂鸟更新(Hummingbird Algorithm)....................................................... 170
7.2.16.1. 上线时间:2013年8月.................................................................. 170
7.2.17. 发薪日贷款算法(Payday Loan Algorithm)............................................. 171
7.2.17.1. 上线时间:2013年6月13号........................................................ 171
7.2.18. 完全匹配域名惩罚(EMD Update).......................................................... 171
7.2.18.1. 上线时间:2012年9月29号........................................................ 172
7.2.19. DMCA惩罚算法(DMCA Takedown Penalty).......................................... 172
7.2.19.1. 上线时间:2012年8月13号........................................................ 172
7.2.20.1. 上线时间:2012年4月24号........................................................ 173
7.2.21. 页面布局惩罚算法(Page Layout Algorithm).......................................... 173
7.2.21.1. 上线时间:2012年1月.................................................................. 173
7.2.22. 新鲜度更新(Freshness Update).............................................................. 174
7.2.22.1. 上线时间:2011年11月3号........................................................ 174
7.2.23.1. 上线时间:2011年2月24号........................................................ 175
7.2.24. 采集惩罚算法(Scraper Algorithm)......................................................... 175
7.2.24.1. 上线时间:2011年1月28号........................................................ 176
7.2.24.1.1. 受影响网站:Matt Cutts的博客帖子公布的这个算法,采集、抄袭的内容页面被惩罚,奖励原出处。2%查询受影响。 176
7.2.25. 负面评价处理(Negative Review)............................................................ 176
7.2.25.1. 上线时间:2010年12月1号........................................................ 176
7.2.26.1. 上线时间:2010年6月1号.......................................................... 177
7.2.27.1. 上线时间:2010年4月28号-5月3号....................................... 177
7.2.28. 页面速度因素(Page Speed Ranking Factor)........................................... 178
7.2.28.1. 上线时间:2010年4月.................................................................. 178
7.2.29. Vince/品牌更新(Vince/Brand Update)................................................... 179
7.2.29.1. 上线时间:2009年2月1号.......................................................... 179
7.2.29.1.1. 受影响网站:大品牌网站页面在很多查询结果中(都是非长尾的大词)排名显著提高,所以最初被称为品牌更新。 179
7.2.30.1. 上线时间:2008年3月.................................................................. 179
7.2.31.1. 上线时间:2005年12月-2006年3月......................................... 180
7.2.32.1. 上线时间:2005年9-11月............................................................. 181
7.2.33.1. 上线时间:2005年5月.................................................................. 181
7.2.34.1. 上线时间:2005年2月.................................................................. 182
7.2.34.1.1. 受影响网站:不明确,或者说范围广泛,包括低质量外链、关键词堆积、过度优化等。 182
7.2.35.1. 上线时间:2005年1月.................................................................. 183
7.2.36.1. 上线时间:2004年2月.................................................................. 183
7.2.37. 弗罗里达更新(Florida Update).............................................................. 184
7.2.37.1. 上线时间:2003年11月................................................................ 184
7.2.38.1. 上线时间:2003年7月.................................................................. 185
7.2.39.1. 上线时间:2003年6月1号.......................................................... 185
7.2.40.1. 上线时间:2003年4月1号.......................................................... 186
7.2.41.1. 上线时间:2003年2月1号.......................................................... 187
7.3.1.1. 对于一些时效性强的搜索(比如突发事件),搜索引擎会给新页面更高的权重。 189
7.3.2.1. 一些模糊搜索词比如“苹果”“大豆”,搜索引擎会给出多样性的搜索结果,因为这些词都用多种含义。 189
7.3.3. 用户浏览历史记录................................................................................. 189
7.3.3.1. 登录Google账号浏览过的网页,以后搜索相关词时,这个网页会在你的本地搜索结果中有一定的排名提升。 189
7.3.5.1. Google会优先考虑使用本地服务器IP和国家/地区特定域名的站点。 190
7.3.6.1. 用户开启安全搜索后,会过滤暴力、色情等非法的搜索结果。 190
7.3.7.1. Google对你添加到Google+ 圈子的作者和网站显示更高的结果。 191
7.3.8.1. Google会降低收到DMCA投诉的页面权重。............................... 191
7.3.9.1. 百度收到举报信息,会针对网站首页不给与展现........................ 191
7.3.10. 搜索结果的域名多样性......................................................................... 191
7.3.10.1. 谷歌2012年6月4日所谓的“大脚怪更新)”据说在每个SERP页面添加了更多域的页面结果。 192
7.3.11.1. Google有时会针对有交易需求的关键字(如航班搜索)显示不同的展示结果。 192
7.3.12.1. Google经常将Google plus的本地搜索结果放在“正常”SERP之上。 192
7.3.13.1. 某些关键字可以触发Google新闻框样式,比如搜”the beatles(甲壳虫乐队)“。 192
7.3.14.1. 在谷歌2009年的”Vince”算法更新后,开始让大品牌的一些短尾词搜索页面排名提升。 193
7.3.15.1. Google有时会在SERP中显示Google购物的结果....................... 193
7.3.16.1. 搜索引擎有时会在搜索里显示一些图片搜索结果列表............... 193
7.3.17.1. 有些搜索结果会出现彩蛋结果,比如:Google有十几个复活节彩蛋结果。 194
7.3.18.1. 域名或品牌关键词会显示同一个网站的多个搜索结果。........... 194
8.1.1. 违背百度谷歌算法................................................................................. 195
8.1.5.1. 把关键字隐藏在html标签里面,如:style tags ,alt tags 等等。 196
8.1.6.1. 隐藏链接对一些搜索引擎来说也会被认为是搜索引擎垃圾技术,但另外一些则不是这样。 197
8.1.9. 链接搜索引擎垃圾技术......................................................................... 198
8.1.9.1. 搜索引擎会认为那些通过自助链接系统建立的链接为搜索引擎垃圾技术。 198
8.2.1. 不自然的导入链接................................................................................. 199
8.2.1.1. 突然(和不自然)的导入链接增加是虚假链接的特征标志............. 199
8.2.2.1. 被Google企鹅算法打击的网站,搜索可见性会变差。.............. 200
8.2.3. 低质量链接占比高................................................................................. 200
8.2.3.1. 黑帽SEO通常使用大量博客评论或论坛链接,很容易识别出作弊。 200
8.2.4.1. 著名的分析MicroSiteMasters.com发现,Google企鹅算法对大量不自然、不相关网站的链接很敏感,有可能做出惩罚。 200
8.2.5.1. Google有些时候会通过Google站长工具给站长发警告信,指出发现大量的非自然外链,随后网站的排名会骤降。 201
8.2.6. 链接来自相同的C类IP......................................................................... 201
8.2.7.1. 大量“非法”锚文本(比如处方药、博彩、小额贷款关键字)指向你的网站,无论哪种方式,都可能会损害你的网站排名。 201
8.2.8.1. 广为所知的是Google曾人工惩罚过英国花卉网站Interflora。.. 202
8.2.9.1. 出售链接肯定会影响PageRank,从而伤害到网站的搜索可见性。 202
8.2.10.1. 新网站突然获得大量外链,一般会被Google放入Google沙盒中,这会影响网站的搜索可见性。 202
8.2.12.1. 使用Google的“链接拒绝工具”可以消除负面SEO受害者网站的人工或算法惩罚。 203
8.2.13.1. 在Google站长工具里提交复议请求,如果成功可以解除惩罚。 203
8.2.14.1. Google显然可以识别先创建,然后再快速删除临时链接以避免惩罚的做法,也被称为临时链接方案。 204
8.3.1.1. 很多有低质量内容(特别是内容农场)的网站在被熊猫算法打击后很难在搜索结果中出现。 205
8.3.2.1. 如果你的网站链接指向到一些敏感网站,像处方药或小额贷款网站,可能会影响你的网站搜索可见性。 205
8.3.3.1. 重定向作弊有很大风险。如果被抓住,面临的可能不只是惩罚,甚至是剔除索引,不再收录。 205
8.3.4. 弹窗广告或诱导广告............................................................................. 205
8.3.4.1. Google网站评分指南指出:弹窗广告或诱导广告是低质量网站的标志。 205
8.3.5.1. 包括很多页面SEO因素,比如关键字堆砌、标题标签堆砌,过度的关键字修饰。 206
8.3.6.1. 许多人反映说,企鹅算法不像熊猫算法那样,企鹅算法会针对具体页面(甚至仅针对特定关键字)处理。 206
8.3.7.1. “页面布局算法”会对拥有大量广告,而且实际内容很少的网站进行惩罚。 206
8.3.8.1. 当试图隐藏联盟链接(特别是隐藏)会带来惩罚。......................... 207
8.3.9.1. Google不喜欢联盟广告公司是公开的秘密。许多人认为,通过联盟链接获利的网站会受到Google额外的审查。 207
8.3.10.1. Google不喜欢自动生成内容的网站。如果Google怀疑你的网站靠机器自动生成内容,可能会导致惩罚或剔除索引(俗称拔毛)。 207
8.3.11.1. 过度操纵PageRank可能会惩罚,比如把所有出站链接或大部分内链都加上Nofollow。 208
8.3.12.1. 如果你的服务器IP地址被标记黑名单(比如大量发垃圾邮件),可能会影响服务器上的所有网站。 208
8.3.13.1. 关键词堆砌也可能发生在Meta标记中。如果Google认为你通过Meta标签作弊,那么他们可能会惩罚你的网站。 208
9.1. 检索词核心权重确定方法和装置................................................................. 210
9.1.1. 申请日:2009年12月18日................................................................ 210
9.1.1.1.1. http://www.soopat.com/Patent/200910242875........................ 211
9.2. 点击有效性的判断方法及其系统................................................................. 211
9.2.1. 申请日:2010年6月18日.................................................................. 211
9.2.1.1.1. http://www.soopat.com/Patent/201010210709........................ 212
9.3. 一种网页分块的重要度评估方法和设备..................................................... 212
9.3.1. 申请日:2010年8月19日.................................................................. 212
9.3.1.1.1. http://www.soopat.com/Patent/201010256704........................ 213
9.4. 一种在网络设备中用于确定关键子词权重的方法和设备......................... 213
9.4.1. 申请日:2010年10月9日.................................................................. 213
9.4.1.1. 获取来自用户的长尾关键词,根据第一预定规则并基于关联关键词来确定所述长尾关键词所包含的多个关键子词的权重 213
9.5. 用于确定字符串信息间相似度信息的方法、装置和设备......................... 213
9.5.1. 申请日:2011年04月20日................................................................ 214
9.5.1.1.1. http://www.soopat.com/Patent/201110099425?lx=FMSQ........ 215
9.6. 基于页面的预置链接关系确定页面权威值的方法与设备......................... 215
9.6.1. 申请日:2010年12月31日................................................................ 215
9.6.1.1.1. http://www.soopat.com/Patent/201010620489?lx=FMSQ........ 216
9.7. 一种用于确定超链接的锚文本可信度的分析设备和方法......................... 216
9.7.1. 申请日:2010年12月31日................................................................ 216
9.7.1.1.1. http://www.soopat.com/Patent/201010620489?lx=FMSQ........ 217
9.8. 挖掘相关实体词的关系关键词的方法和装置及其应用............................. 217
9.8.1. 申请日:2011年3月28日.................................................................. 217
9.8.1.1.1. http://www.soopat.com/Patent/201110075248?lx=FMSQ........ 218
9.9. 基于非线性统一权值对检索结果进行排序的方法及装置......................... 218
9.9.1. 申请日:2011年3月28日.................................................................. 218
9.9.1.1.1. http://www.soopat.com/Patent/201110075248?lx=FMSQ........ 219
9.10. 确定站点的领域信息以及相关性判定方法、系统及设备-公开................ 219
9.10.1. 申请日:2011年5月9日.................................................................... 220
9.10.1.1.1. http://www.soopat.com/Patent/201110118083?lx=FMSQ...... 221
9.11. 一种用于确定图片相似度的方法与设备..................................................... 221
9.11.1. 申请日:2011年6月28日.................................................................. 221
9.11.1.1.1. http://www.soopat.com/Patent/201110180020...................... 222
9.12. 建立需求分析模板的方法、搜索需求识别的............................................. 222
9.12.1. 申请日:2011年9月9日.................................................................... 222
9.13. 一种挖掘具有相似需求的查询的方法及装置............................................. 223
9.13.1. 申请日:2011年11月23日................................................................ 223
9.13.1.1.1. http://www.soopat.com/Patent/201110376378...................... 224
9.14. 一种挖掘具有相似需求的查询的方法及装置............................................. 224
9.14.1. 申请日:2011年11月24日................................................................ 224
9.14.1.1.1. http://www.soopat.com/Patent/201110379429?lx=FMSQ...... 225
9.15. 一种应用的泛需求检索方法及系统............................................................. 225
9.15.1. 申请日:2013年2月22日.................................................................. 225
9.15.1.1.1. http://www.soopat.com/Patent/201310056283?lx=FMSQ...... 226
9.16. 得到和搜索结构化语义知识的方法及对应................................................. 226
9.16.1. 申请日:2011年12月28日................................................................ 227
9.16.1.1.1. http://www.soopat.com/Patent/201110447926?lx=FMSQ...... 228
9.17. 原创内容的搜索方法和搜索服务器............................................................. 228
9.17.1. 申请日:2013年04月27日................................................................ 228
9.17.1.1.1. http://www.soopat.com/Patent/201310153664?lx=FMSQ...... 229
9.18. 搜索候选词的推荐方法及搜索引擎............................................................. 229
9.18.1. 申请日:2013年5月7日.................................................................... 229
9.18.1.1.1. http://www.soopat.com/Patent/201310165048?lx=FMSQ...... 230
9.19. 生成共现关键词的方法、提供关联搜索词的方法以及系统..................... 231
9.19.1. 申请日:2013年5月8日.................................................................... 231
9.19.1.1.1. http://www.soopat.com/Patent/201310165690?lx=FMSQ...... 232
9.20. 搜索引擎中相关性策略之间耦合度的分析方法及装置............................. 232
9.20.1. 申请日:2013年6月4日.................................................................... 232
9.20.1.1.1. http://www.soopat.com/Patent/201310219735?lx=FMSQ...... 233
9.21. 一种搜索结果的生成方法和装置................................................................. 233
9.21.1. 申请日:2012年02月23日................................................................ 233
9.21.1.1.1. http://www.soopat.com/Patent/201711468186...................... 234
9.22. 一种用于获取页面相似度的方法与设备..................................................... 234
9.22.1. 申请日:2012年03月29日................................................................ 234
9.22.1.1.1. http://www.soopat.com/Patent/201210089360?lx=FMSQ...... 235
9.23. 提取关键词的方法和设备............................................................................. 235
9.23.1. 申请日:2013年11月29日................................................................ 236
9.23.1.1.1. http://www.soopat.com/Patent/201310627998...................... 236
9.24. 一种根据海量数据进行应用相似度判断的方法及系统............................. 236
9.24.1. 申请日:2012年07月10日................................................................ 236
9.24.1.1.1. http://www.soopat.com/Patent/201210238193...................... 237
9.25. 一种评估网页权威性的方法及装置............................................................. 237
9.25.1. 申请日:2012年08月31日................................................................ 238
9.25.1.1.1. http://www.soopat.com/Patent/201210320005?lx=FMSQ...... 238
9.26. 基于关键词进行检索的方法及装置............................................................. 239
9.26.1. 申请日:2013年12月20日................................................................ 239
9.26.1.1.1. http://www.soopat.com/Patent/201310710834...................... 239
9.27. 一种网站重点页面的挖掘方法及装置......................................................... 240
9.27.1. 申请日:2012年09月29日................................................................ 240
9.27.1.1.1. http://www.soopat.com/Patent/201210380363?lx=FMSQ...... 240
9.28. 一种提取领域关键词的方法及装置............................................................. 240
9.28.1. 申请日:2014年03月19日................................................................ 241
9.28.1.1.1. http://www.soopat.com/Patent/201410101751?lx=FMSQ...... 241
9.29. 一种寻址类查询词的挖掘方法及系统......................................................... 242
9.29.1. 申请日:2012年12月11日................................................................ 242
9.29.1.1.1. http://www.soopat.com/Patent/201210533948?lx=FMSQ...... 243
9.30. 一种用于确定页面中的垃圾文本信息的方法与设备................................. 243
9.30.1. 申请日:2014年02月20日................................................................ 243
9.30.1.1.1. http://www.soopat.com/Patent/201410058591...................... 244
9.31. 确定目标关键词所对应的搜索相关性类别的方法和设备......................... 244
9.31.1. 申请日:2012年12月27日................................................................ 244
9.31.1.1.1. http://www.soopat.com/Patent/201210581476?lx=FMSQ...... 245
9.32. 一种识别垃圾信息的方法与装置................................................................. 245
9.32.1. 申请日:2014年4月1日.................................................................... 246
9.32.1.1.1. http://www.soopat.com/Patent/201410128835...................... 247
9.33. 生成关联关键词、提供关联关键词的方法及系统..................................... 247
9.33.1. 申请日:2014年09月24日................................................................ 247
9.33.1.1.1. http://www.soopat.com/Patent/201410494326?lx=FMSQ...... 248
9.34. 查询语句与网页相似度的确定方法、装置、终端及服务器..................... 248
9.34.1. 申请日:2014年10月29日................................................................ 248
9.34.1.1.1. http://www.soopat.com/Patent/201410592231...................... 249
9.35. 网页打分模型的创建方法及装置................................................................. 249
9.35.1. 申请日:2014年11月06日................................................................ 249
9.35.1.1.1. http://www.soopat.com/Patent/201410638360?lx=FMSQ...... 250
9.36. 确定短文本相似度的方法和装置................................................................. 250
9.36.1. 申请日:2014年11月11日................................................................ 251
9.36.1.1.1. http://www.soopat.com/Patent/201410645486?lx=FMSQ...... 251
9.37. 作弊文本的识别方法和系统......................................................................... 252
9.37.1. 申请日:2014年11月13日................................................................ 252
9.37.1.1.1. http://www.soopat.com/Patent/201410641811...................... 252
9.38. 通过计算机实现的计算文本相似度和搜索处理方法及装置..................... 252
9.38.1. 申请日:2014年12月03日................................................................ 253
9.38.1.1.1. http://www.soopat.com/Patent/201410728432?lx=FMSQ...... 254
9.39. 语义相似度计算方法、搜索结果处理方法和装置..................................... 254
9.39.1. 申请日:2014年12月02日................................................................ 254
9.39.1.1.1. http://www.soopat.com/Patent/201410721307?lx=FMSQ...... 255
9.40. 语句相似度的计算、搜索处理方法及装置................................................. 255
9.40.1. 申请日:2014年12月02日................................................................ 255
9.40.1.1.1. http://www.soopat.com/Patent/201410722755?lx=FMSQ...... 256
9.41. 恶意点击的防御方法和装置......................................................................... 256
9.41.1. 申请日:2015年01月26日................................................................ 256
9.41.1.1.1. http://www.soopat.com/Patent/201510038602?lx=FMSQ...... 257
9.42. 提取文档中关键词的方法及装置................................................................. 257
9.42.1. 申请日:2015年08月19日................................................................ 258
9.42.1.1.1. http://www.soopat.com/Patent/201510512363?lx=FMSQ...... 258
9.43. 提取文档关键句的方法及装置..................................................................... 258
9.43.1. 申请日:2015年09月15日................................................................ 259
9.43.1.1.1. http://www.soopat.com/Patent/201510587652?lx=FMSQ...... 259
9.44. 知识数据的处理方法和装置......................................................................... 259
9.44.1. 申请日:2015年09月30日................................................................ 260
9.44.1.1.1. http://www.soopat.com/Patent/201510640181?lx=FMSQ...... 260
9.45. 查询结果的底层召回方法和装置................................................................. 261
9.45.1. 申请日:2016年05月11日................................................................ 261
9.45.1.1.1. http://www.soopat.com/Patent/201610309835...................... 262
9.46. 基于深度问答的答案检索方法及装置......................................................... 262
9.46.1. 申请日:2016年12月28日................................................................ 262
9.46.1.1.1. http://www.soopat.com/Patent/201611235007...................... 263
9.47. 用于识别网站的方法、装置及服务器......................................................... 263
9.47.1. 申请日:2017年01月26日................................................................ 263
9.47.1.1.1. http://www.soopat.com/Patent/201710057271...................... 264
9.48. 基于人工智能的网页原创性识别方法、装置............................................. 264
9.48.1. 申请日:2017年03月11日................................................................ 264
9.48.1.1.1. http://www.soopat.com/Patent/201710209215...................... 265
9.49. 基于人工智能的文章价值评估方法、装置及存储介质............................. 265
9.49.1. 申请日:2017年06月06日................................................................ 265
9.49.1.1.1. http://www.soopat.com/Patent/201710417749...................... 266
9.50. 基于人工智能的低质量文章识别方法及装置、设备及介质..................... 266
9.50.1. 申请日:2017年06月20日................................................................ 266
9.50.1.1.1. http://www.soopat.com/Patent/201710469542...................... 267
9.51. 文本相似度的处理方法、装置、设备和计算机存储介质......................... 267
9.51.1. 申请日:2017年09月18日................................................................ 267
9.51.1.1.1. http://www.soopat.com/Patent/201710841945...................... 268
9.52. 检索文本相关性的评估方法、装置、服务器和存储介质......................... 268
9.52.1. 申请日:2017年12月07日................................................................ 268
9.52.1.1.1. http://www.soopat.com/Patent/201711284320...................... 269
9.53. 标题生成方法、装置和电子设备................................................................. 269
9.53.1. 申请日:2017年12月20日................................................................ 270
9.53.1.1.1. http://www.soopat.com/Patent/201711384836...................... 271
9.54. 网站质量评估方法及装置............................................................................. 271
9.54.1. 申请日:2016年11月30日................................................................ 271
9.54.1.1.1. http://www.soopat.com/Patent/201611082107...................... 271
9.55. 文本核心词识别方法和装置......................................................................... 272
9.55.1. 申请日:2017年01月19日................................................................ 272
9.55.1.1.1. http://www.soopat.com/Patent/201710044590...................... 273
9.56. 评论数据处理方法、装置及设备................................................................. 273
9.56.1. 申请日:2018年04月10日................................................................ 273
9.56.1.1.1. http://www.soopat.com/Patent/201810317233...................... 274
9.57. 文本作弊的识别方法及装置......................................................................... 274
9.57.1. 申请日:2018年04月28日................................................................ 274
9.57.1.1.1. http://www.soopat.com/Patent/201810398470...................... 275
9.58. 页面正文提取方法和装置............................................................................. 275
9.58.1. 申请日:2018年06月01日................................................................ 276
9.58.1.1.1. http://www.soopat.com/Patent/201810554392...................... 277
9.59. 对话内容连贯性的判断方法、装置以及设备............................................. 277
9.59.1. 申请日:2018年06月29日................................................................ 277
9.59.1.1.1. http://www.soopat.com/Patent/201810694536...................... 278
9.60. 问题答案类型的确定方法、装置、设备及存储介质................................. 278
9.60.1. 申请日:2018年06月29日................................................................ 278
9.60.1.1.1. http://www.soopat.com/Patent/201810695686...................... 279
9.61. 一种确定搜索结果的方法、装置、设备和计算机存储介质..................... 279
9.61.1. 申请日:2018年06月08日................................................................ 280
9.61.1.1.1. http://www.soopat.com/Patent/201810587495...................... 281
9.62. 搜索结果排序方法和装置............................................................................. 281
9.62.1. 申请日:2018年07月05日................................................................ 281
9.62.1.1.1. http://www.soopat.com/Patent/201810729232...................... 282
9.63. 一种网页重复的判断系统及其判断方法..................................................... 282
9.63.1. 申请日:2011年01月28日................................................................ 282
9.63.1.1.1. http://www.soopat.com/Patent/201110031636...................... 283
9.64. 重复网页识别方法和装置............................................................................. 283
9.64.1. 申请日:2014年07月08日................................................................ 283
9.64.1.1.1. http://www.soopat.com/Patent/201410324553...................... 284
9.65. 一种应用的离线缓存方法和系统................................................................. 284
9.65.1. 申请日:2017年11月15日................................................................ 285
9.65.1.1.1. http://www.soopat.com/Patent/201711128645...................... 285
9.66. 离线下载方法和离线下载服务器................................................................. 285
9.66.1. 申请日:2013年05月02日................................................................ 285
9.66.1.1.1. http://www.soopat.com/Patent/201310158954...................... 286
9.67. 在线性页面结构下用于页面非线性跳转的方法和设备............................. 286
9.67.1. 申请日:2014年07月18日................................................................ 286
9.67.1.1.1. http://www.soopat.com/Patent/201410345839...................... 287
9.68. 视频选择播放方法、装置、设备和可读存储介质..................................... 288
9.68.1. 申请日:2019年07月16日................................................................ 288
9.68.1.1.1. http://www.soopat.com/Patent/201910641968...................... 289
9.69. 文本表示方法、装置、设备和存储介质..................................................... 289
9.69.1. 申请日:2019年06月11日................................................................ 289
9.69.1.1.1. http://www.soopat.com/Patent/201910504977...................... 290
9.70.1. 申请日:2019年05月28日................................................................ 290
9.70.1.1.1. http://www.soopat.com/Patent/201910452219...................... 291
9.71.1. 申请日:2019年05月13日................................................................ 292
9.71.1.1.1. http://www.soopat.com/Patent/201910392924...................... 293
9.72. 文章判重处理方法、装置及电子设备......................................................... 293
9.72.1. 申请日:2019年05月13日................................................................ 293
9.72.1.1.1. http://www.soopat.com/Patent/201910394044...................... 294
9.73. 页面错误识别方法和装置............................................................................. 294
9.73.1. 申请日:2019年05月10日................................................................ 294
9.73.1.1.1. http://www.soopat.com/Patent/201910389806...................... 295
1. 域名因素
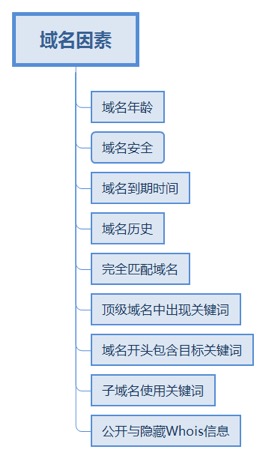
1.1. 域名年龄

1.1.1. 谷歌知名工程师Matt Cutts曾在这个Youtube视频中说过:“注册6个月与注册一年的域名差别不那么大”。换句话说:Google确实使用域名年龄作为一种因素考虑,但权重不高。
1.2. 域名安全
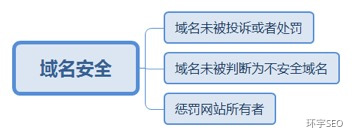
1.2.1. 域名未被投诉或者处罚

1.2.1.1. 域名注册申请者提供域名持有者真实、准确、完整的身份信息等域名注册信息。
1.2.1.2. 字体侵权
1.2.1.3. 品牌侵权
1.2.1.4. 违反广告法,违禁词
1.2.2. 域名未被判断为不安全域名
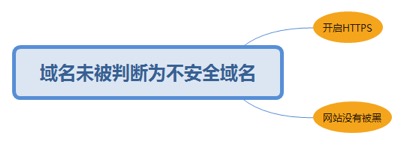
1.2.2.1. 开启https
1.2.2.2. 网站没有被黑
1.2.3. 惩罚网站所有者

1.2.3.1. 如果某人被识别为垃圾邮件发送者,那Google会仔细检查该人拥有的网站是否有意义。
1.3. 域名到期时间

1.3.1. Google于2015年3月31日申请了“基于历史数据的信息检索”的专利,某世界知名SEO讨论也讨论过其中的细节,暗示Google确实研究域名注册和更新日期。(1) 域名注册日期可以作为网站成立日期的参考(2) 域名的一些信息有助于区分合法和非法网站,有价值的网站(合法)一般会多支付几年的域名费用,而违法、灰色行业则很少使用超过一年。
所以打算好好做网站的朋友多续费几年域名吧。
1.4. 域名历史

1.4.1. 如果域名所有权几经更迭,那Google可能会重置网站的历史记录,以前域名的反向链接价值会被丢掉。
1.5. 完全匹配域名

1.5.1. 如果域名和关键词完全一致,如果网站质量很高,这依然是优势。否则反而更容易被识别惩罚。
1.6. 顶级域名中出现关键词

1.6.1. 不像过去有助于提升排名,但域名中的关键词仍然作为相关性的一种信号。
1.7. 域名开头包含目标关键词

1.7.1. 在域名开头包含目标关键词,相对于不含关键词或尾部包含关键词的域名有优势。
1.8. 子域名使用关键词
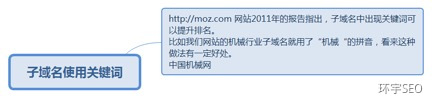
1.8.1. http://moz.com 网站2011年的报告指出,子域名中出现关键词可以提升排名。
比如我们网站的机械行业子域名就用了“机械“的拼音,看来这种做法有一定好处。
中国机械网
1.9. 公开与隐藏Whois信息

1.9.1. Matt Cutts在2006年的Pubcon会议中说到:”当检查网站的Whois时,发现不少都有隐私保护服务,这很不寻常。…打开Whois隐私保护并不是默认的(不少是收费服务),如果把这些因素放到一起考虑,你的网站会被归到某个类别对待(打开隐私保护的站),而不独立了(可能被牵连)“
2. 页面因素
2.1. TDK
2.1.1. 标题Title质量
2.1.1.1. 标题中包含关键词

2.1.1.1.1. 标题是第二重要的页面因素(除页面内容之外),在页面SEO优化中作用巨大。
根据http://Moz.com的数据,标题开头使用关键词比结尾使用效果要好
还有Meta description中出现关键词也是高相关性的信号,现在不是特别重要,但依然有些用。
2.1.1.2. Title中的潜在索引关键词

2.1.1.2.1. 潜在语义分析(Latent Semantic Analysis)或者潜在语义索引(Latent Semantic Index),是1988年S.T. Dumais等人提出的一种新的信息检索代数模型,是用于知识获取和展示的计算理论和方法,它使用统计计算的方法对大量的文本集进行分析,从而提取出词与词之间潜在的语义结构,并用这种潜在的语义结构来表示词和文本,达到消除词之间的相关性和简化文本向量实现降维的目的。

2.1.1.2.1.1. <u>https://wenku.baidu.com/view/64118259804d2b160b4ec03a.html</u>
2.1.2. 描述Description质量
2.1.2.1. Description中的包含关键词
2.1.2.2. Description中的潜在索引关键词
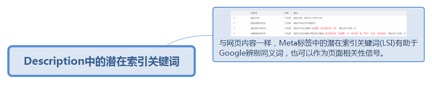
2.1.2.2.1. 与网页内容一样,Meta标签中的潜在索引关键词(LSI)有助于Google辨别同义词,也可以作为页面相关性信号。

2.2. 内容相关性
2.2.1. H标签
2.2.1.1. H1标签中出现关键词
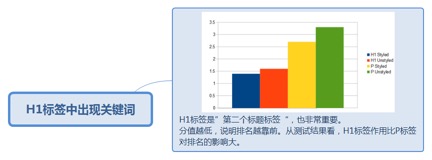
2.2.1.1.1. H1标签是”第二个标题标签“,也非常重要。
分值越低,说明排名越靠前。从测试结果看,H1标签作用比P标签对排名的影响大。
2.2.1.2. H2/H3标签中出现关键词

2.2.1.2.1. 将关键词显示在H2或H3标签的副标题中是另一个弱相关信号。
2.2.2. 关键词布局
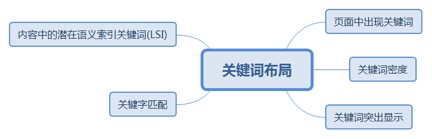
2.2.2.1. 页面中出现关键词

2.2.2.1.1. 页面中有关键词比其他任何相关性都更有说服力。
2.2.2.2. 关键词密度

2.2.2.2.1. 虽然不像以前那么重要,但依然会被Google用来确定网页主题。但关键词密度过大会有反作用。
2.2.2.3. 关键词突出显示

2.2.2.3.1. 关键词出现在页面前100个字中似乎是一个重要的相关信号。
2.2.2.4. 关键字匹配

2.2.2.4.1. 关键词全字匹配更重要,比如搜索“cat shaving techniques(给猫剃毛技术)”,针对完全匹配做的优化页面就比“techniques for shaving a cat”要好,虽然意思一样。
2.2.2.5. 内容中的潜在语义索引关键词(LSI)

2.2.2.5.1. 潜在语义索引关键词(Latent Semantic Indexing = LSI)帮助搜索引擎从多义词中提取具体意义(比如 Apple 识别为苹果公司还是苹果这个水果),所以页面中出现的其他相关词很重要。是否存在LSI词可能作为内容质量的评判标准。

2.2.3. 内容
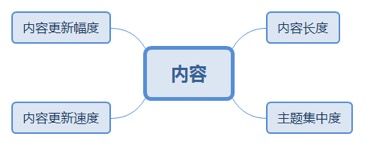
2.2.3.1. 内容长度

2.2.3.1.1. 文章长一般会包含更多关键词,涵盖的内容也会更广泛,与短小精悍的文章比有优势。SERPIQ网站发现内容长度与搜索结果排名相关。
测试结果:平均长度为2500个单词的文章排名效果最好,不知道有没有人针对百度测试过中文页面篇幅对搜索结果的影响。
2.2.3.1.2. 句子长度
2.2.3.1.3. 段落长度
2.2.3.2. 主题集中度
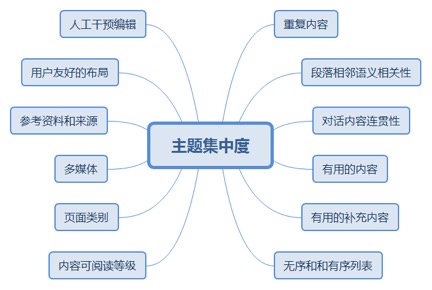
2.2.3.2.1. 重复内容

2.2.3.2.1.1. 同一网站上的相同内容(可能稍作修改)可能会对网站搜索引擎的收录和排名有负面影响。
2.2.3.2.1.2. 页面上的内容是否是原创?如果是从Google索引页面中采集或复制的,它不会获得和原始内容一样的排名。
2.2.3.2.2. 段落相邻语义相关性
2.2.3.2.3. 对话内容连贯性
2.2.3.2.4. 有用的内容

2.2.3.2.4.1. 正如Backlinko读者Jared Carrizales所指出,Google可能会区分“高质量”和“有用的”内容的不同。
2.2.3.2.5. 有用的补充内容

2.2.3.2.5.1. 根据Google公布的评分指南文件,有用的补充内容是网页质量的指标(也是排名指标),比如货币换算器、贷款利息计算器等。
2.2.3.2.6. 无序和和有序列表

2.2.3.2.6.1. 有序列表有助于为读者分解内容,用户体验会更好。Google可能更喜欢使用列表的内容。
2.2.3.2.7. 内容可阅读等级

2.2.3.2.7.1. Google会评估网页的阅读难度。但这条规则有争议,有人认为容易阅读的浅显内容有助于吸引读者,还能提升排名,而有些人则认为容易被认为是内容工厂。
2.2.3.2.8. 页面类别
2.2.3.2.8.1. 页面出现在什么类别是一个相关信号,如果页面和类别不相关,则很难获得好的排名。(信息要发布到正确的分类)
2.2.3.2.9. 多媒体
2.2.3.2.9.1. 图像,视频和其他多媒体元素可以作为内容质量信号。
2.2.3.2.10. 参考资料和来源
2.2.3.2.10.1. 引用参考资料和来源,如学术论文,可能是高质量内容的标志。Google质量指南规定,引用页面时应注意来源:“是否是专业知识或权威来源,这很很重要”。不过,Google否认他们使用外部链接作为排名因素。
2.2.3.2.11. 用户友好的布局

2.2.3.2.11.1. 这里再次引用Google质量指南文件:“高质量的页面布局会让页面主体部分很容易被用户看到”。
2.2.3.2.12. 人工干预编辑
2.2.3.2.12.1. 人工编辑影响搜索引擎结果页(SERP)
2.2.3.3. 内容更新速度
2.2.3.3.1. 页面年龄

2.2.3.3.1.1. 虽然搜索引擎喜欢新鲜的内容,但是定期更新的旧页面可能会超过新页面。
2.2.3.3.2. Google Caffeine算法对时间敏感的搜索很重视,表现就是搜索结果会显示内容更新时间。
2.2.3.4. 内容更新幅度

2.2.3.4.1. 编辑和更新也是一个页面新鲜度因素。添加或删除整个段落才算重要更新,不能只是调换一些词的顺序。
2.2.3.4.2. 页面历史更新频次

2.2.3.4.2.1. 页面多久更新?每天、每周、每隔5年?页面更新频率在提升页面新鲜度中起到重要作用。
2.3. 竞争能力
2.3.1. 网页所在域名权重

2.3.1.1. 如果其他一切条件相同,权重高的域名页面排名更好。
2.3.2. 页面PageRank
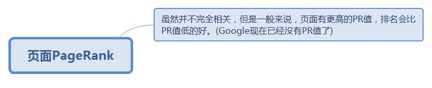
2.3.2.1. 虽然并不完全相关,但是一般来说,页面有更高的PR值,排名会比PR值低的好。(Google现在已经没有PR值了)
2.3.3. 其他关键字的排名页面数量

2.3.3.1. 如果页面获得了其他关键字的排名,那么这个词的排名权重可能会提升。
2.3.4. 停靠域名
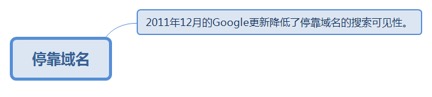
2.3.4.1. 2011年12月的Google更新降低了停靠域名的搜索可见性。
2.4. 速度
2.4.1. 域名解析速度
2.4.2. 页面加载速度
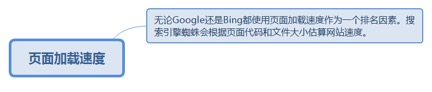
2.4.2.1. 无论Google还是Bing都使用页面加载速度作为一个排名因素。搜索引擎蜘蛛会根据页面代码和文件大小估算网站速度。
2.4.3. Chrome浏览器访问速度

2.4.3.1. Google可能会使用Chrome的用户数据来识别与HTML代码无关的页面加载速度情况。
2.5. 链接
2.5.1. 出站链接
2.5.1.1. 出站链接质量

2.5.1.1.1. 链接指向权重网站有助于向Google发送信任信号。
2.5.1.2. 出站链接主题

2.5.1.2.1. 根据http://Moz.com的试验,搜索引擎可以使用你链接指向的页面作为相关性信号。例如:你有一个汽车相关的页面链接指向了一个电影相关的页面,这可能会告诉Google你的页面是关于汽车电影的,而不只是单指“汽车”。
2.5.1.3. 出站链接数
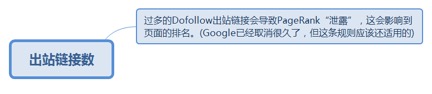
2.5.1.3.1. 过多的Dofollow出站链接会导致PageRank“泄露”,这会影响到页面的排名。(Google已经取消很久了,但这条规则应该还适用的)
2.5.1.4. 太多出站链接

2.5.1.4.1. 有些网页有太多导出链接,会干扰和分散主要内容。
2.5.2. 指向链接
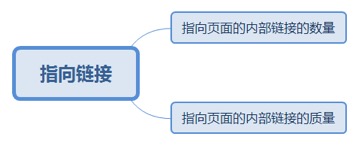
2.5.2.1. 指向页面的内部链接的数量

2.5.2.1.1. 网站内链数量表明它相对于其他页面的重要性,越多越重要。
2.5.2.2. 指向页面的内部链接的质量

2.5.2.2.1. 网站里高权重(PR)页面的内链效果比低权重(或无权重)的效果好很多。
2.5.3. 联盟链接

2.5.3.1. 联盟链接(Affiliate Link)本身可能不会影响排名。但如果太多的话,Google的算法可能会更加注意你网站的其他质量信号,以确保网站不是一个单薄的联盟链接网站。
2.5.4. 死链数量

2.5.4.1. 页面太多死链是网站被遗弃或没人维护的特征,Google会使用死链来评估网站首页质量。
2.6. URL
2.6.1. URL路径
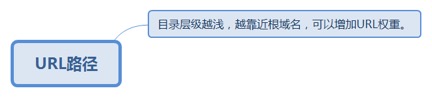
2.6.1.1. 目录层级越浅,越靠近根域名,可以增加URL权重。
2.6.2. URL中的关键字
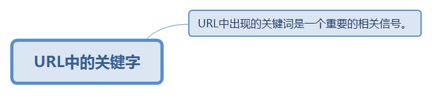
2.6.2.1. URL中出现的关键词是一个重要的相关信号。
2.6.3. URL字符串

2.6.3.1. Google会自动识别URL字符串中的目录和分类,可以识别出页面主题。
2.6.4. 网址长度
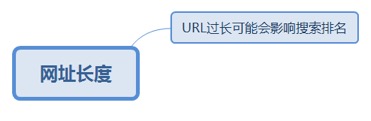
2.6.4.1. URL过长可能会影响搜索排名
2.7. 标签
2.7.1. HTML错误和W3C验证

2.7.1.1. 网站页面很多HTML错误可能是质量差的特征。虽然这点有争议,但很多SEOer认为,网页不能通过W3C验证是一种网站质量差的信号。
2.7.2. rel=”canonical”标记

2.7.2.1. 合理使用 rel="canonical"标记,会防止Google误判网站内容重复而惩罚。
2.7.3. 图像优化

2.7.3.1. 图片的文件名、Alt文本、Title、Description和Caption都是重要的页面相关性指标。
2.7.3.2. Alt标签(用于图像链接)
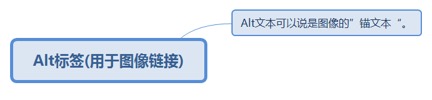
2.7.3.2.1. Alt文本可以说是图像的”锚文本“。
2.7.4. Sitemap中页面优先级

2.7.4.1. Sitemap.xml文件中指定的页面优先级可能会影响排名。
2.7.5. 语法和拼写

2.7.5.1. 正确的语法和拼写是一个页面质量信号。
2.7.6. WordPress标签

2.7.6.1. 标签是WordPress特定的相关信号。改善搜索引擎优化效果的唯一方法是将一个内容与另一个内容相关联,更具体地说是将一组内容相互关联。
3. 网站级因素
3.1. 域名信任度

3.1.1. 域名获得多少来自种子站点(搜索引擎极度青睐的抓取起始站点)的链接是一个非常重要的排名因素。TrustRank站说明)
3.2. 内容
3.2.1. 内容可以提供价值和独特的见解
3.2.2. 网站更新

3.2.2.1. 网站的更新频次,尤其是添加新内容时。这是一个很好的提升网站新鲜度的信号。
3.2.3. 网站页面数量
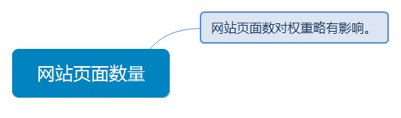
3.2.3.1. 网站页面数对权重略有影响。
3.2.4. 联系我们页面
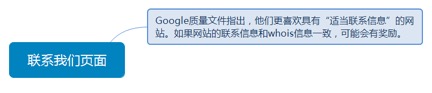
3.2.4.1. Google质量文件指出,他们更喜欢具有“适当联系信息”的网站。如果网站的联系信息和whois信息一致,可能会有奖励。
3.2.5. 服务条款和隐私页面

3.2.5.1. 这两个页面有助于告诉Google你的网站是值得信赖的。
3.2.6. 时间因子
3.2.6.1. 落地页时间因子是百度搜索判断网站收录、展示、排序结果的重要参考依据。

3.2.6.1.1. 首页|栏目-最新时间
3.2.6.1.2. 专题|内容-发布时间
3.3. 网站架构
3.3.1. 一个很好的整合网站架构(尤其是一个仓筒结构)可以帮助Google识别和抓取、组织你的内容。
仓筒结构的理解就是把同一类内容放到不同的目录下,就像农民会把小麦、大麦、燕麦放到独立的仓库,如果混在一起,只能称之为”谷物“,反而降低了价值。
3.3.2. 结构要点:将同类型和主题的页面放在一起;分离不相关的页面;加强每个目录的着陆页。
3.3.3. 重复的Meta标签内容

3.3.3.1. 网站页面使用重复一样的Meta keywords和Description可能会降低你的所有页面可见性。
3.3.4. 面包屑导航(Breadcrumb)

3.3.4.1. 拥有面包屑导航是用户体验良好的网站结构风格,可以帮助用户(和搜索引擎)知道他们在网站上的位置。
3.3.5. 移动版优化
3.3.5.1. 谷歌的官方建议是创建一个响应式网站。响应式网站可能会在移动搜索中获得优势。Google还会对移动搜索结果中没有移动版的页面进行降权。
3.4. 站点地图

3.4.1. 站点地图有助于搜索引擎更轻松、更彻底地抓取和索引你的页面,提高页面可见性(搜索排名)。
3.5. 网站正常运行时间

3.5.1. 网站经常维护或宕机可能会影响排名(如果没有及时修复,甚至可能导致减少索引量)
3.6. 服务器位置
3.6.1. 服务器位置可能会影响网站在不同地区的排名,对于地域相关的搜索特别重要。
3.7. SSL证书

3.7.1. 已经确认Google百度会索引SSL证书,并使用HTTPS作为排名信号。
3.8. 网站可用性
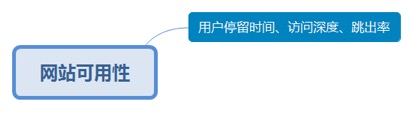
3.8.1. 用户停留时间、访问深度、跳出率
3.9. 站长统计代码 站长分析代码

3.9.1. 百度统计、百度站长工具、360站长、神马站长、Sogou站长、谷歌分析
3.10. 主动推送代码
3.11. 用户评价/网站声誉

3.11.1. http://Yelp.com和http://RipOffReport.com可能在Google这个算法中发挥了重要作用。Google甚至发布了他们抓住了一个利用用户差评获得反向链接的案例。
国内应对对应的就是百度口碑网站了:百度口碑
4. 反向链接因素
4.1. 链接质量
4.1.1. 链接的域名年龄
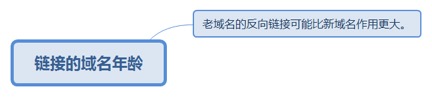
4.1.1.1. 老域名的反向链接可能比新域名作用更大。
4.1.2. 独立C类IP的链接数

4.1.2.1. 来自不同C类IP(Class-C)数量越多,说明链接广泛性越好
4.1.3. 来自.edu或.gov类域名链接

4.1.3.1. 虽然Google的Matt Cutts说不会做区别对待。但是,这并不妨碍广大SEOer认为Google对.gov和.edu域名的权重算法中有特殊的地方,也就说大家认为来自教育机构和政府网站的链接价值更大。
4.1.4. 链接域名的权重

4.1.4.1. 同等页面权重下,域名权重越高越好(PR3站点的PR2页面权重小于PR8网站的PR2页面)。
4.1.5. 链接域相关性

4.1.5.1. 来自类似主题的利基站点(垂直网站)链接比来自完全不相关网站的链接更强大。有效的SEO策略依然着重于获得相关链接。
4.1.6. 页面级相关性

4.1.6.1. Hilltop算法指出,与页面内容紧密相关的链接权重比不相关页面链接权重更高。(百度专利)
4.1.7. 链接页面的权重

4.1.7.1. 反向链接的页面权重(PageRank)是非常重要的排名因素。(百度专利)
4.1.7.2. 导入链接的用户点击 链接流量(百度专利)
4.1.8. 来自竞争对手的链接

4.1.8.1. 如果你能获得关键词搜索结果中其他网站的反向链接,则对于关键词排名特别有价值。
4.1.9. 来自网站首页的链接
4.1.9.1. 来自网站首页的链接权重比内页的要高很多。
4.1.10. 链接类型的多样性

4.1.10.1. 如果链接都来自某单一来源,比如论坛个人资料和博客评论页面,这明显不自然,会容易识别为垃圾链接。而来自不同来源的链接则是自然链接的标志。
4.1.11. 社会化网站引用页面

4.1.11.1. 被社会化(设计)网站引用可能会影响链接的价值,被引用的越多越好。
4.1.12. 专业主题链接
4.1.12.1. Aaron Wall声称,从专业的相关主题页面获取的的链接会给予更高的权重。
4.1.13. 权威网站链接

4.1.13.1. 从公认的行业权威网站获得的链接比小的专题网站获得好处多。
4.1.14. 维基百科的引用链接

4.1.14.1. 虽然添加有nofollow标签,但很多人认为,从维基百科获取链接可以让你的网站在搜索引擎眼中增添一点信任和权威。
国内可以增加一些来自百度百科和互动百科的引用。
4.1.15. 反向链接添加时间

4.1.15.1. 根据Google专利,以前添加的链接比新加的反向链接具有更多的权重。 更新时间(百度专利)
4.1.16. 真实网站链接与垃圾博客链接

4.1.16.1. Google给“真实网站”的链接权重比垃圾博客链接高。Google可能会使用品牌和用户互动信号来区分两者。
4.1.17. 自然链接
4.1.17.1. 拥有“自然链接”的网站将排名高,而且排名更稳定持久。
4.1.18. 互惠链接
4.1.18.1. Google指出“过度链接交换”是一种作弊,需要避免。
4.1.19. 链接网站的可信度(TrustRank)

4.1.19.1. 网站的可信度也可以传递,如果很多可信度高的网站指向到你网站,对排名有好处。
4.1.20. 页面的出站链接数量

4.1.20.1. 页面的PageRank是有限的,导出链接多的页面比导出少的效果差。
4.1.21. 来自论坛的链接
4.1.21.1. 由于大量作弊,Google可能会大大降低论坛中链接的权重。
4.1.22. 全站链接
4.1.22.1. Matt Cutts已经确认,全站链接被“压缩”识别为单个链接。
4.1.23. 用户帖子引用

4.1.23.1. 虽然让用户发布引用链接是白帽SEO的一部分,但如果链接来自签名或简介部分,价值可能不如页面内容里的相关链接,尽量能让用户帖子内容里加链接。
4.1.24. 用户生成的内容链接
4.1.24.1. Google能够识别用户生成(UGC)的链接与实际的网站所有者添加的链接。
例如:Google知道来自Wordpress官方博客上的链接与用户创建的wordpress博客http://joesblog.wordpress.com链接是非常不同的。
4.1.25. Nofollow链接

4.1.25.1. SEO中最有争议的话题之一。Google的官方话是:“一般来说,我们不跟随他们。”这表明他们至少在某些特定情况下会Follow,拥有一定百分比的nofollow链接可用于区分自然与非自然的链接。
4.1.26. 赞助链接

4.1.26.1. 像“合作伙伴”、“赞助商链接”这样的词语可能会降低其附近链接的价值。
4.1.27. 来自301跳转的链接

4.1.27.1. 经过301重定向的链接与直接链接相比可能会损失一点点权重,然而Google的Matt Cutts说:301链接类似于直接链接。
4.1.28. 引荐域的国家/地区

4.1.28.1. 从国家/地区的顶级域名(.de,.cn,.http://co.uk)获取链接可能会帮助网站在该国家排名更好。
4.1.29. DMOZ收录
4.1.29.1. 许多人认为,Google会给被http://DMOZ.com收录的网站更多的信任和权重。
4.1.30. 过多301重定向页面

4.1.30.1. 根据Google网站管理员帮助视频,过多301重定向链接会稀释部分(甚至全部)PR 。
4.1.31. 来自垃圾网站的链接
4.1.31.1. 来自垃圾网站的链接可能会伤害网站排名。
4.2. 链接内容质量
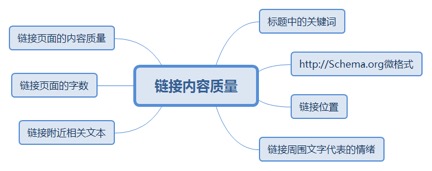
4.2.1. 标题中的关键词
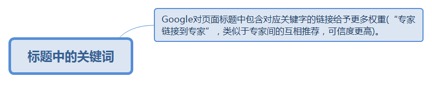
4.2.1.1. Google对页面标题中包含对应关键字的链接给予更多权重(“专家链接到专家”,类似于专家间的互相推荐,可信度更高)。
4.2.2. http://Schema.org微格式

4.2.2.1. 支持Schema微格式的页面可以在Google的搜索结果中出现,从而直接提升搜索结果页的点击率这是不争的事实。
4.2.3. 链接位置
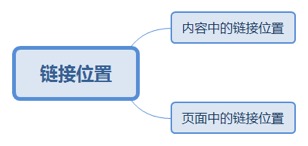
4.2.3.1. 内容中的链接位置
4.2.3.1.1. 在内容开头的链接比内容结尾的链接权重高。
4.2.3.2. 页面中的链接位置

4.2.3.2.1. 通常,在页面主体内容中添加的链接比页面底部或侧边栏中的链接权重更高。
4.2.4. 链接周围文字代表的情绪

4.2.4.1. Google可能已经可以根据链接周围文本识别出情绪,分析出链接是推荐还是负面批评引用。
4.2.5. 链接附近相关文本

4.2.5.1. 在反向链接周围出现的文本有助于告诉Google你的页面主题。
4.2.6. 链接页面的字数

4.2.6.1. 1000字帖子中的链接比25个字帖中的链接更有价值。
4.2.7. 链接页面的内容质量

4.2.7.1. 拼写错误多,语句不通内容里的链接价值不如专业包含多媒体内容里的链接。
4.3. 锚文本
4.3.1. 链接标题
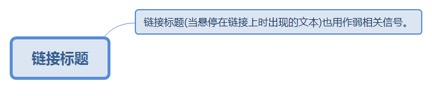
4.3.1.1. 链接标题(当悬停在链接上时出现的文本)也用作弱相关信号。
4.3.2. 反向链接锚文本
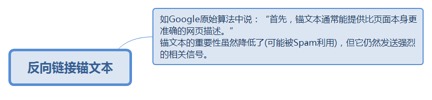
4.3.2.1. 如Google原始算法中说:“首先,锚文本通常能提供比页面本身更准确的网页描述。”锚文本的重要性虽然降低了(可能被Spam利用),但它仍然发送强烈的相关信号。
4.3.3. 内部链接锚文本

4.3.3.1. 内部链接锚文本是另一个相关性的信号,虽然可能与反向链接的锚文本权重不同。
4.4. 链接数量
4.4.1. 链接的域名数量
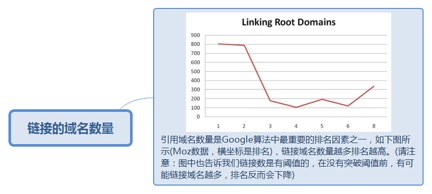
4.4.1.1. 引用域名数量是Google算法中最重要的排名因素之一,如下图所示(Moz数据,横坐标是排名),链接域名数量越多排名越高。(请注意:图中也告诉我们链接数是有阈值的,在没有突破阈值前,有可能链接域名越多,排名反而会下降)
4.4.2. 链接页数
4.4.2.1. 链接页面的总数很重要, 即使部分都来自同一个域名,这也对排名有帮助。
4.4.3. 链接添加减少速度
4.4.3.1. 正链接速度

4.4.3.1.1. 链接增加速度(反向链接增加速度快于减少速度)的网站通常会得到搜索结果排名提升。
4.4.3.2. 负链接速度

4.4.3.2.1. 链接减少速度(反向链接减少速度快于增加速度))可以显著降低排名,因为它是流行度下降的信号。
5. 用户互动
5.1. 搜索关键词的页面点击率

5.1.1. 搜索结果中点击率高的页面可能会获得该特定关键字的排名提升。百度算法也是这样,这就是各种“网页快排”技术的理论基础。
5.2. 所有搜索关键词的页面点击率

5.2.1. 所有关键字的网页(或网站)的点击率都是基于人的交互信号,一般都是点击率越高越好。
一定要重视优化SERP(搜索结果页),其中页面标题、配图、图标,都是SEO改进的点,以便提升用户的点击率。
5.3. 跳出率
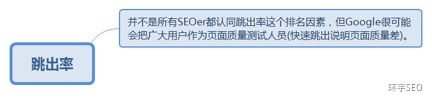
5.3.1. 并不是所有SEOer都认同跳出率这个排名因素,但Google很可能会把广大用户作为页面质量测试人员(快速跳出说明页面质量差)。
5.4. 直接流量

5.4.1. 已经确认Google使用Google Chrome的数据来确定人们是否访问网站(以及访问频率)。拥有大量直接流量的网站可能比直接流量少的网站质量更高。
5.5. 重复流量
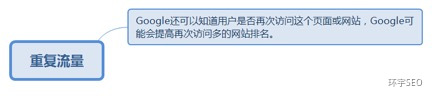
5.5.1. Google还可以知道用户是否再次访问这个页面或网站,Google可能会提高再次访问多的网站排名。
5.6. 评论数
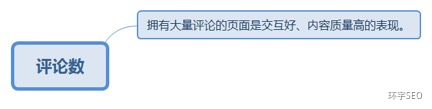
5.6.1. 拥有大量评论的页面是交互好、内容质量高的表现。
5.7. 停留时间
5.7.1. 搜索引擎非常注意“停留时间”:搜索引擎搜索过来的人在你的页面停留了多长时间。
可能是”长点击(点击页面后停留时间长)“,也可能是”短点击(点击页面后停留时间短)“如果人们花费大量时间在你的网站上,搜索引擎会认为网站质量很好。
5.8. 被阻止的网站
5.8.1. Google熊猫2.0算法仍然用这个数据作为质量信号。
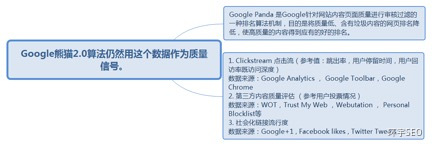
5.8.1.1. Google Panda 是Google针对网站内容页面质量进行审核过滤的一种排名算法机制,目的是将质量低、含有垃圾内容的网页排名降低,使高质量的内容得到应有的好的排名。
5.8.1.2. 1. Clickstream 点击流(参考值:跳出率,用户停留时间,用户回访率既访问深度)
数据来源:Google Analytics , Google Toolbar,Google Chrome
2. 第三方内容质量评估 (参考用户投票情况)
数据来源:WOT,Trust My Web ,Webutation , Personal Blocklist等3. 社会化链接流行度
数据来源:Google+1 , Facebook likes , Twitter Tweets
5.9. 书签|收藏夹

5.9.1. 被用户加入浏览器书签的页面可能会提升排名。
5.10. Google工具栏数据

5.10.1. Danny Goodwin报道Google使用工具栏数据作为排名信号。但是,除了检测页面加载速度和恶意软件之外,不知道Google还从工具栏收集什么数据。
6. 品牌信号
6.1. 品牌名锚文本

6.1.1. 品牌名锚文本是一个简单而强大的品牌信号。
6.2. 品牌搜索
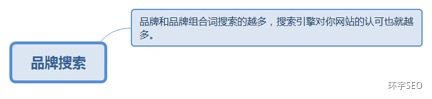
6.2.1. 品牌和品牌组合词搜索的越多,搜索引擎对你网站的认可也就越多。
6.3. 新闻网站的品牌曝光

6.3.1. 真正的大品牌能在新闻中找到很多相关信息。事实上,一些品牌甚至在搜索结果首页有新闻列表。
6.4. 知名媒体的曝光度
6.4.1. 谷歌
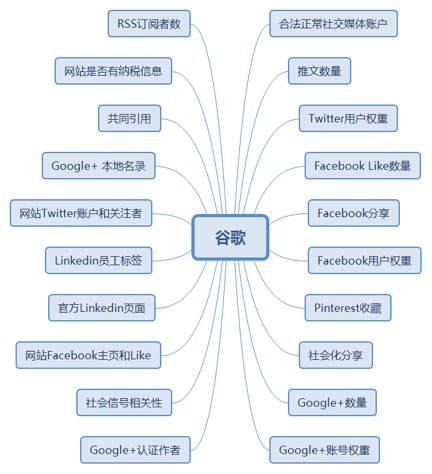
6.4.1.1. 合法正常社交媒体账户

6.4.1.1.1. 同样拥有10,000关注者,跟关注者互动多的比少的好很多。
6.4.1.2. 推文数量
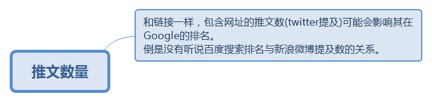
6.4.1.2.1. 和链接一样,包含网址的推文数(twitter提及)可能会影响其在Google的排名。
倒是没有听说百度搜索排名与新浪微博提及数的关系。
6.4.1.3. Twitter用户权重

6.4.1.3.1. 粉丝多,创建早,影响力大的Twitter号比来自新的、低影响力的帐户的推文链接更有影响力。
6.4.1.4. Facebook Like数量
6.4.1.4.1. 虽然Google看不到大多数Facebook帐户,但有他们可能把Facebook Like数量当作弱排名信号。
6.4.1.5. Facebook分享
6.4.1.5.1. Facebook分享与反向链接更相似,应该比Facebook Like数量更有影响力。
6.4.1.6. Facebook用户权重

6.4.1.6.1. 粉丝多、影响大的Facebook账号上的分享和Like数据,搜索引擎会传达更多权重。
6.4.1.7. Pinterest收藏
6.4.1.7.1. Pinterest是一个很流行的社会化媒体网站,拥有大量的公开资料。Google可能用Pinterest的数据作为排名信号。
6.4.1.8. 社会化分享
6.4.1.8.1. Google可能会用Reddit,Stumbleupon和Digg等网站的分享作为另一种排名信号。
6.4.1.9. Google+数量
6.4.1.9.1. 虽然Matt Cutts明确说过Google+对排名“没有直接影响 ”,但很难相信他们会忽略自己的社交网络。
6.4.1.10. Google+账号权重
6.4.1.10.1. 从逻辑上说,Google会更看重权威账号的权重。
6.4.1.11. Google+认证作者

6.4.1.11.1. 2013年2月,Google首席执行官埃里克·施密特(Eric Schmidt)声称:“在搜索结果中,已验通过验证的Google+账户排名将高于未验证的账户”尽管Google+作者身份计划已关闭,但Google可能会使用某种形式的身份认证来确定有影响力的在线内容创作者(并提高排名)。
6.4.1.12. 社会信号相关性
6.4.1.12.1. Google可能会用分享的内容和链接周围文字判断相关性。
6.4.1.13. 网站Facebook主页和Like

6.4.1.13.1. 品牌往往拥有Facebook主页,而且Like数很多。
6.4.1.14. 官方Linkedin页面
6.4.1.14.1. 大多数真实企业在Linkedin上都有页面。
6.4.1.15. Linkedin员工标签

6.4.1.15.1. Rand Fishkin认为让员工们开通LinkedIn帐号,并在资料中填写公司名称有助于增强公司品牌信号。
6.4.1.16. 网站Twitter账户和关注者

6.4.1.16.1. 知名流行品牌的Twitter账户往往有大量关注者。
6.4.1.17. Google+ 本地名录

6.4.1.17.1. 在Google+ 本地名录中找到意味着网站有实体办公室,Google用此来确定你的网站是否为一个大品牌。
6.4.1.18. 共同引用

6.4.1.18.1. 品牌在内容中被提及但没有链接指向,Google可能将这种没有链接的品牌提及作为品牌信号。共同引用算法有效降低了外链和锚文本的作用,依然可以识别出某些页面的主题,从而提升关键词排名。
6.4.1.19. 网站是否有纳税信息

6.4.1.19.1. http://Moz.com指出Google可能看一个网站是否提供税务信息。
6.4.1.20. RSS订阅者数

6.4.1.20.1. 考虑到Google拥有受欢迎的Feedburner RSS服务,他们将RSS订阅数作为人气和品牌信号是有意义的。(现在RSS已经不流行了,不知道Google是否还会使用这个因素)
6.4.2. 百度
6.4.2.1. 网站社交信号
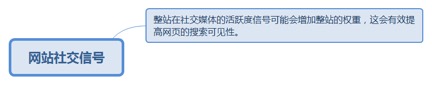
6.4.2.1.1. 整站在社交媒体的活跃度信号可能会增加整站的权重,这会有效提高网页的搜索可见性。
6.4.2.2. 百度账号
6.4.2.3. 百度文库
6.4.2.4. 百度知道
6.4.2.5. 百家号
6.4.2.6. 知乎
6.4.2.7. 熊掌号
6.4.2.8. 百度小程序
6.4.2.9. 公众号
6.4.2.10. 头条号
6.4.2.11. 大鱼号
6.4.2.12. 微博
7. 特殊算法规则
7.1. 百度算法(2013-2019)

7.1.1. 网站内容质量
7.1.1.1. 百度飓风算法
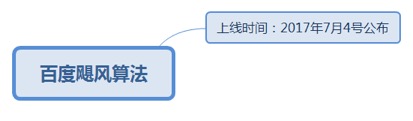
7.1.1.1.1. 上线时间:2017年7月4号公布

7.1.1.1.1.1. 打击对象:严厉打击以恶劣采集为内容主要来源的网站。

7.1.1.1.1.1.1. <u>https://ziyuan.baidu.com/wiki/1050</u>
7.1.1.2. 百度飓风算法2.0
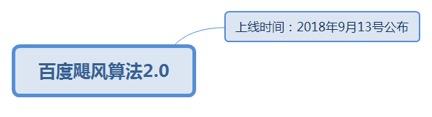
7.1.1.2.1. 上线时间:2018年9月13号公布
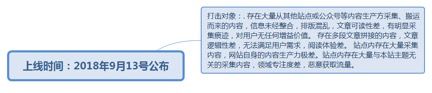
7.1.1.2.1.1. 打击对象:. 存在大量从其他站点或公众号等内容生产方采集、搬运而来的内容,信息未经整合,排版混乱,文章可读性差,有明显采集痕迹,对用户无任何增益价值。 存在多段文章拼接的内容,文章逻辑性差,无法满足用户需求,阅读体验差。 站点内存在大量采集内容,网站自身的内容生产力极差。站点内存在大量与本站主题无关的采集内容,领域专注度差,恶意获取流量。

7.1.1.2.1.1.1. <u>https://ziyuan.baidu.com/wiki/2585</u>
7.1.1.3. 百度飓风算法3.0
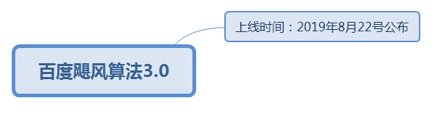
7.1.1.3.1. 上线时间:2019年8月22号公布

7.1.1.3.1.1. 打击对象:针对跨领域采集以及站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序等内容。

7.1.1.3.1.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=2850</u>
7.1.1.4. 百度蓝天算法
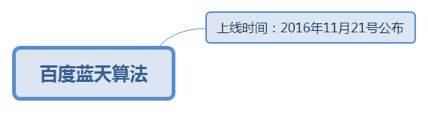
7.1.1.4.1. 上线时间:2016年11月21号公布

7.1.1.4.1.1. 重点打击买卖软文的网站,包括新闻源和其他一些高权重网站,违规网站会受到降低权重排名。

7.1.1.4.1.1.1. <u>https://ziyuan.baidu.com/wiki/933</u>
7.1.1.5. 百度极光算法
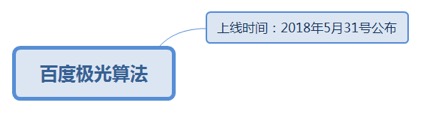
7.1.1.5.1. 上线时间:2018年5月31号公布

7.1.1.5.1.1. 旨在倡导资源方重视网站落地页时间规范。落地页时间因子是百度搜索判断网站收录、展示、排序结果的重要参考依据。

7.1.1.5.1.1.1. <u>https://ziyuan.baidu.com/wiki/2245</u>
7.1.1.6. 百度搜索下载站质量规范
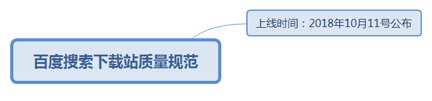
7.1.1.6.1. 上线时间:2018年10月11号公布

7.1.1.6.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=2653</u>
7.1.1.7. 百度搜索落地页时间因子规范
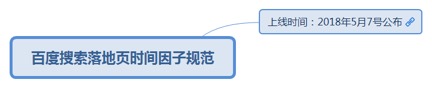
7.1.1.7.1. <u>上线时间:2018</u><u>年5</u><u>月7</u><u>号公布</u>

7.1.1.7.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=2210</u>
7.1.2. 用户需求满足
7.1.2.1. 百度清风算法

7.1.2.1.1. 上线时间:2017年9月14号公布,9月底上线

7.1.2.1.1.1. 打击对象:提过页面标题作弊,欺骗用户获得点击的行为。

7.1.2.1.1.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=1659</u>
7.1.2.2. 百度闪电算法

7.1.2.2.1. 上线时间:2017年10月19号公布,10月初已上线

7.1.2.2.1.1. 主要影响:移动页面首屏加载时间将影响搜索排名

7.1.2.2.1.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=1591</u>
7.1.2.3. 百度清风算法2.0
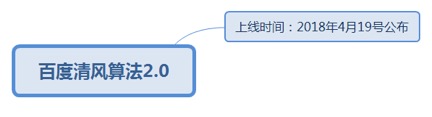
7.1.2.3.1. 上线时间:2018年4月19号公布

7.1.2.3.1.1. 打击对象:严厉打击欺骗下载

7.1.2.3.1.1.1. 1.实际下载的资源与需求不符
7.1.2.3.1.1.2. 2. 提供了下载链接、实际站点无下载资源
<u>https://ziyuan.baidu.com/wiki/2160</u>(1.实际下载的资源与需求不符, 2. 提供了下载链接、实际站点无下载资源)
7.1.2.4. 百度细雨算法
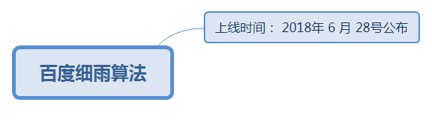
7.1.2.4.1. 上线时间: 2018年 6 月 28号公布

7.1.2.4.1.1. 1.页面标题作弊,包含冒充官网,title堆砌关键词等情况;2. 商家为了在页面中频繁保留联系方式而做出的各种低质受益行为,如受益方式变形、穿插受益等。
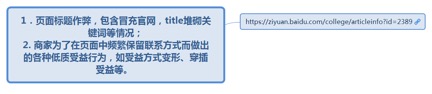
7.1.2.4.1.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=2389</u>
7.1.2.5. 百度清风算法3.0
7.1.2.5.1. 上线时间:2018年10月16号公布

7.1.2.5.1.1. 打击对象:对下载站的标题作弊、欺骗下载、捆绑下载等问题进行全面审查

7.1.2.5.1.1.1. <u>https://ziyuan.baidu.com/wiki/2664</u>
7.1.2.6. 百度搜索网页标题规范
7.1.2.6.1. 上线时间:2018年10月15号

7.1.2.6.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=2728</u>
7.1.2.7. 严厉打击虚假诈骗等违法违规信息的公告

7.1.2.7.1. 上线时间:2019年2月27号公布

7.1.2.7.1.1. 打击对象:严厉打击电信网络中的虚假诈骗、违法交易、黄赌毒等违法违规信息。

7.1.2.7.1.1.1. <u>https://ziyuan.baidu.com/wiki/2770</u>
7.1.2.8. 百度信风算法
7.1.2.8.1. 上线时间:2019年5月22号公布

7.1.2.8.1.1. 打击对象:利用翻页键诱导用户的行为

7.1.2.8.1.1.1. <u>https://ziyuan.baidu.com/wiki/2789</u>
7.1.3. 搜索恶意竞争
7.1.3.1. 百度绿萝算法
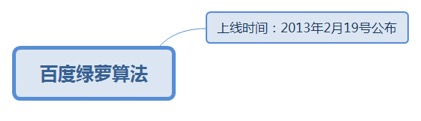
7.1.3.1.1. 上线时间:2013年2月19号公布

7.1.3.1.1.1. 打击对象:买卖链接的行为,包括超链中介、出卖链接的网站、购买链接的网站。

7.1.3.1.1.1.1. <u>https://ziyuan.baidu.com/wiki/142</u>
7.1.3.2. 百度绿萝算法2.0
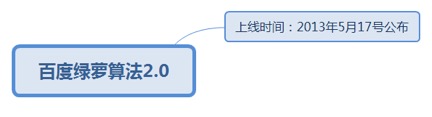
7.1.3.2.1. 上线时间:2013年5月17号公布

7.1.3.2.1.1. 打击对象:软文中的外链及惩罚发软文的站点。

7.1.3.2.1.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=30</u>
7.1.3.3. 百度惊雷算法

7.1.3.3.1. 上线时间:2017年11月20号公布,2017年11月底上线

7.1.3.3.1.1. 打击对象:严厉打击通过刷点击,提升网站搜索排序的作弊行为;以此保证搜索用户体验,促进搜索内容生态良性发展。

7.1.3.3.1.1.1. <u>https://ziyuan.baidu.com/wiki/1686</u>
7.1.3.4. 百度惊雷算法2.0
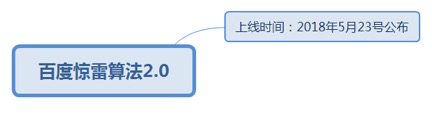
7.1.3.4.1. 上线时间:2018年5月23号公布

7.1.3.4.1.1. 此次升级主要针对“恶意制造作弊超链”和“恶意刷点击”的作弊行为进行了算法升级。惊雷算法2.0将对作弊的网站限制搜索展现、清洗作弊链接、清洗点击,并会将站点作弊行为计入站点历史,严重者将永久封禁。还请存在问题的站点尽快自查整改。

7.1.3.4.1.1.1. <u>https://ziyuan.baidu.com/wiki/2235</u>
7.1.4. 网站安全问题
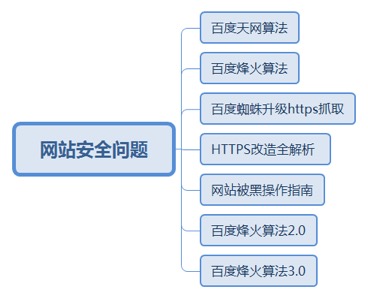
7.1.4.1. 百度天网算法
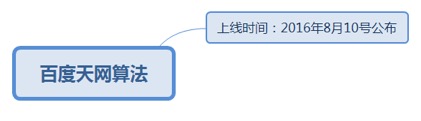
7.1.4.1.1. 上线时间:2016年8月10号公布

7.1.4.1.1.1. 重点打击网站JS代码恶意套取用户隐私信息,如套电手机号、QQ号等行为,网站清理掉违规JS可解除百度惩罚。

7.1.4.1.1.1.1. <u>https://ziyuan.baidu.com/wiki/883</u>
7.1.4.2. 百度烽火算法
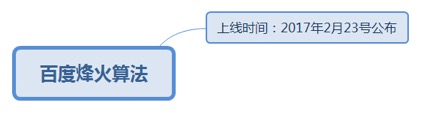
7.1.4.2.1. 上线时间:2017年2月23号公布
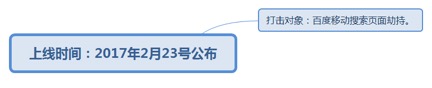
7.1.4.2.1.1. 打击对象:百度移动搜索页面劫持。

7.1.4.2.1.1.1. <u>https://ziyuan.baidu.com/wiki/968</u>
7.1.4.3. 百度蜘蛛升级https抓取
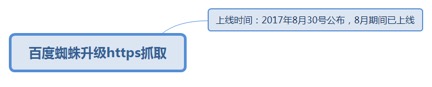
7.1.4.3.1. 上线时间:2017年8月30号公布,8月期间已上线

7.1.4.3.1.1. 主要影响:升级了对HTTPS数据的抓取力度,HTTPS数据将更快被Spider抓取到。
7.1.4.4. HTTPS改造全解析
7.1.4.4.1. 上线时间:2018年2月5号公布

7.1.4.4.1.1. <u>https://zy.baidu.com/actxzh/https?isResponsible=1</u>
7.1.4.5. 网站被黑操作指南
7.1.4.5.1. 上线时间:2018年3月21号公布

7.1.4.5.1.1. <u>https://ziyuan.baidu.com/college/articleinfo?id=1949</u>
7.1.4.6. 百度烽火算法2.0
7.1.4.6.1. 上线时间:2018年5月17号公布

7.1.4.6.1.1. 1. 未经用户允许恶意窃取用户手机号码等隐私数据的行为。2. 恶意劫持百度流量的行为,主要表现在:
(1)搜索用户通过百度移动搜索到达网站后,完成阅读要离开网站页面时,通过浏览器返回上一级页面被劫持到虚假的百度搜索结果页中;
(2)搜索用户通过百度移动搜索到达网站后,完成阅读要离开网站页面时,通过浏览器始终无法返回上一级百度搜索结果页,搜索用户会一直被困在站点内。 
7.1.4.6.1.1.1. <u>https://ziyuan.baidu.com/wiki/2222</u>
7.1.4.7. 百度烽火算法3.0
7.1.4.7.1. 上线时间:2019年3月14号公布
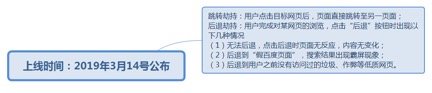
7.1.4.7.1.1. 跳转劫持:用户点击目标网页后,页面直接跳转至另一页面;
后退劫持:用户完成对某网页的浏览,点击“后退”按钮时出现以下几种情况
(1)无法后退,点击后退时页面无反应,内容无变化;
(2)后退到“假百度页面”,搜索结果出现霸屏现象;
(3)后退到用户之前没有访问过的垃圾、作弊等低质网页。 
7.1.4.7.1.1.1. <u>https://ziyuan.baidu.com/wiki/2778</u>
7.1.5. 落地页体验问题
7.1.5.1. 百度石榴算法
7.1.5.1.1. 上线时间:2013年5月17号

7.1.5.1.1.1. 打击对象:大量妨碍用户正常浏览的恶劣广告的页面、低质量内容页面

7.1.5.1.1.1.1. <u>https://ziyuan.baidu.com/wiki/174</u>
7.1.5.2. 百度冰桶算法1.0
7.1.5.2.1. 上线时间:2014年8月22号
7.1.5.2.1.1. 打击对象:移动端影响用户体验的落地页。

7.1.5.2.1.1.1. <u>https://ziyuan.baidu.com/wiki/313</u>
7.1.5.3. 百度冰桶算法2.0
7.1.5.3.1. 上线时间:2014 年 11 月 18 日

7.1.5.3.1.1. 打击对象:全屏下载、在狭小的手机页面布设大面积广告遮挡主体内容、强制用户登录才可以使用等。

7.1.5.3.1.1.1. <u>https://ziyuan.baidu.com/wiki/697</u>
7.1.5.4. 百度冰桶算法3.0
7.1.5.4.1. 上线时间:2016年7月7号公布,7月15号上线

7.1.5.4.1.1. 打击对象:打断用户完整搜索路径的行为。

7.1.5.4.1.1.1. <u>https://ziyuan.baidu.com/wiki/870</u>
7.1.5.5. 百度冰桶算法4.0
7.1.5.5.1. 上线时间:2016年9月19号公布

7.1.5.5.1.1. 打击对象:广告过多、影响用户体验的移动页面。

7.1.5.5.1.1.1. <u>https://ziyuan.baidu.com/wiki/900</u>
7.1.5.6. 百度冰桶算法4.5
7.1.5.6.1. 上线时间:2016年10月26号公布

7.1.5.6.1.1. 打击对象:发布恶劣诱导类广告的页面。

7.1.5.6.1.1.1. <u>https://ziyuan.baidu.com/wiki/911</u>
7.1.5.7. 百度冰桶算法5.0
7.1.5.7.1. 上线时间:2018年11月12号公布

7.1.5.7.1.1. 保障搜索用户体验
7.1.5.7.1.1.1. <u>https://ziyuan.baidu.com/wiki/2723</u>
7.1.5.8. 百度移动搜索落地页体验白皮书4.0

7.1.5.8.1. 上线时间:2018年8月15号公布

7.1.5.8.1.1. <u>https://ziyuan.baidu.com/college/documentinfo?id=2492</u>
7.1.5.9. 严厉打击色情低俗广告内容
7.1.5.9.1. 上线时间:2019年1月23号公布

7.1.5.9.1.1. <u>https://ziyuan.baidu.com/wiki/2758</u>
7.1.5.10. 严格控制搜索中的权限问题
7.1.5.10.1. 上线时间:2019年4月18号公布

7.1.5.10.1.1. <u>https://ziyuan.baidu.com/wiki/2785</u>
7.2. 谷歌算法
7.2.1. 马加比更新(Maccabees Update)

7.2.1.1. 上线时间:2017年12月12号

7.2.1.1.1. 受影响网站:刻意为各种关键词组合建立大量着陆页,比如“地名A+服务a“、”地名A+服务b”、“地名B+服务a”等等,为了覆盖这些关键词,制造大量页面,质量通常不会高。
7.2.2. 移动优先索引(Mobile First Index)
7.2.2.1. 上线时间:2017年10月中旬
7.2.2.1.1. 受影响网站:移动优先索引指的是Google优先索引网站移动版本,并作为排名依据。以前都是索引PC版本并计算排名的。移动优先索引Google在2016年底就开始宣传了,但一直没有推出,估计影响面比较大。2017年10月中旬左右,Google透露一小部分网站已经开始转为移动优先索引。
7.2.3. 猫头鹰更新(Project Owl)
7.2.3.1. 上线时间:2017年4月25号

7.2.3.1.1. 受影响网站:虚假新闻内容,如编造的假新闻,极度偏见、煽动仇恨,谣言等。参见以前写的关于猫头鹰算法的帖子。
7.2.4. 弗雷德更新(Fred Update)

7.2.4.1. 上线时间:2017年3月8号

7.2.4.1.1. 受影响网站:广告过多的低质量内容站,这类网站之所以存在,就是为了放 Adsense之类的广告,并没有提供给用户更多价值。
7.2.5. 移动页面干扰插页惩罚算法(Intrusive Interstitial Penalty)

7.2.5.1. 上线时间:2017年1月10号

7.2.5.1.1. 受影响网站:这个惩罚算法针对移动页面:挡住主题内容的弹窗,干扰用户访问的大幅插页式广告,用户需要关掉插页才能看到页面实际内容,有时候需要等5-10秒才能关掉。不过据统计,被惩罚的网站并不多。
7.2.6. 企鹅更新4.0(Penguin 4.0)

7.2.6.1. 上线时间:2016年9月23号,10月12号左右完成

7.2.6.1.1. 受影响网站:和以前的企鹅更新一样,受影响的是有低质量外链的网站。Penguin 4.0是最后一次企鹅系列算法更新了,因为企鹅算法以后成为核心排名算法的一部分,实时更新。
7.2.7. 移动友好算法2(Mobile Friendly Algorithm 2)

7.2.7.1. 上线时间:2016年4月21号

7.2.7.1.1. 受影响网站:2015年4月21号第一次Google移动友好算法的一次更新,使更多移动友好页面能被用户看到。
7.2.8. APP安装插页广告惩罚(APP Install Interstitial Penalty)

7.2.8.1. 上线时间:2015年11月2号
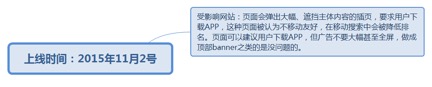
7.2.8.1.1. 受影响网站:页面会弹出大幅、遮挡主体内容的插页,要求用户下载APP,这种页面被认为不移动友好,在移动搜索中会被降低排名。页面可以建议用户下载APP,但广告不要大幅甚至全屏,做成顶部banner之类的是没问题的。
7.2.9. RankBrain
7.2.9.1. 上线时间:2015年10月26号

7.2.9.1.1. RankBrain严格说来不算是排名算法,而是以人工智能为基础的深入理解用户查询词的系统,尤其是长尾的、不常出现的查询。2015年刚上线时,15%查询词经过RankBrain处理,可能是效果很好,2016年开始所有查询词都经过RankBrain处理。
7.2.10. 被黑网站删除算法(Hacked Spam)

7.2.10.1. 上线时间:2015年10月

7.2.10.1.1. 受影响网站:被黑的网站,包括病毒、引导流量到色情、侵权产品、非法药物网站等。这些页面会从搜索结果这直接删除,所以有时候搜索结果页面可能只有8、9个结果。以前通常是在搜索结果中标注这个页面可能被黑了,现在直接删除了。5%左右的查询受到影响。检查自己网站是否被黑还是挺重要的。
7.2.11. 熊猫算法4.2(Panda Update 4.2)

7.2.11.1. 上线时间:2015年7月18号

7.2.11.1.1. 自2011年推出以来,熊猫算法经历了近30次更新,Panda 4.2是最后一次,几个月才完成。这之后,熊猫算法成为Google核心算法的一部分,虽然还会有更新,但不再单独给名字了。
7.2.12. 质量更新(Quality Update)
7.2.12.1. 上线时间:2015年5月1号左右

7.2.12.1.1. 受影响网站:内容质量低的页面,但不是熊猫算法。Google虽然确认了这次更新,但表示,这只是Google经常做的算法更新之一,调整了评估内容质量的方法,没什么特殊的。
7.2.13. 移动友好算法(Mobile Friendly Algorithm)

7.2.13.1. 上线时间:2015年4月21号

7.2.13.1.1. 受影响网站:在移动搜索中给予移动友好的网站排名提升。也被称为Mobilegeddon – 天劫算法。
所谓移动友好,其实没那么复杂,用户能正常在手机访问页面就行了,所以字体不要太小,字距行距不要太小,用户不需要左右拉屏幕,手指头点击链接时不会点错地方,速度够快等等。自己用手机看看自己网站就知道是否移动友好了。也可以参考一下本博客移动SEO的帖子。
移动友好算法是针对页面级别的,需要页面重新抓取、索引后才能判断是否移动友好。所以算法本身4月底上线,但受影响的页面可能不是马上见到效果。
7.2.14. HTTPS更新(HTTPS Update)

7.2.14.1. 上线时间:2014年8月7号

7.2.14.1.1. 受影响网站:使用了https的页面排名会稍微提升一点。Google声明这只是个很小的排名因素,但事实上对网站采用https起到了很大推动作用。
7.2.15. 鸽子更新(Pigeon Update)

7.2.15.1. 上线时间:2014年7月24号

7.2.15.1.1. 受影响网站:鸽子更新是本地搜索算法的一次更新,改进了距离和定位排名算法参数。这个名字不是Google起的,是SearchEngineLand给起的。之所以取“鸽子”这个名字是因为,鸽子会回家,有本地意识。
7.2.16. 蜂鸟更新(Hummingbird Algorithm)
7.2.16.1. 上线时间:2013年8月

7.2.16.1.1. 受影响网站:蜂鸟更新是一次排名算法的重写,改进对查询词真实意图的理解,更重要的是未来的扩展性。虽然代码是完全重写的,但排名因素及参数大概变化不多,所以上线后基本上SEO行业没有人注意到。
7.2.17. 发薪日贷款算法(Payday Loan Algorithm)

7.2.17.1. 上线时间:2013年6月13号
7.2.17.1.1. 受影响网站:针对垃圾和黑帽手法盛行的一些行业的查询词重点打击,如payday loan(发薪日贷款,一种小额、短期、利息高的贷款,一般下个发薪日就还上)、色情等。这些行业常用的作弊手法也经常是非法的。
2014年5月16号,发薪日贷款算法2.0上线,2014年6月12号,算法3.0上线。
7.2.18. 完全匹配域名惩罚(EMD Update)

7.2.18.1. 上线时间:2012年9月29号

7.2.18.1.1. 受影响网站:低质量的完全匹配域名(exact match domain)网站,也就是域名与目标关键词完全一样。URL中包含关键词对排名有一些帮助,所以不少SEO用目标关键词注册域名。这种域名确实有过好处,但现在内容不行的话可能被惩罚。
7.2.19. DMCA惩罚算法(DMCA Takedown Penalty)

7.2.19.1. 上线时间:2012年8月13号

7.2.19.1.1. 受影响网站:DMCA,Digital Millennium Copyright Act,数字千年版权法案,根据这个法案,版权作品被侵权,版权所有人可以向服务商要求删除侵权内容,服务商可以是主机商,域名注册商,ISP,以及搜索引擎。DMCA算法就是对收到很多侵权投诉删除要求的网站,Google给予排名惩罚。DMCA Takedown Penalty又被称为pirate update,海盗算法。2014年10月21号,DMCA惩罚算法上线2.0版本,很多BT种子网站、视频网站被大幅惩罚。
7.2.20. 企鹅更新(Penguin Update)

7.2.20.1. 上线时间:2012年4月24号

7.2.20.1.1. 受影响网站:Google的官方帖子声明打击的是违反Google质量指南的垃圾网站,后续排名变化的分析表明主要受惩罚的是为获得排名制造大量垃圾外链、低质量外链的网站。企鹅算法1.0影响了3.1%英文查询,3%左右的中文、德文等查询。
7.2.21. 页面布局惩罚算法(Page Layout Algorithm)

7.2.21.1. 上线时间:2012年1月

7.2.21.1.1. 受影响网站:第一屏显示过多广告的页面被降低排名。因此也常被称为Ads Above The Fold(第一屏广告)算法。1%的查询词受影响。被惩罚的网站修改页面布局后,Google重新抓取、索引,如果页面用户体验已经改善,就会自动恢复。2012年10月9号,Page Layout 2.0,2014年2月6号,Page Layout 3.0分别上线。
7.2.22. 新鲜度更新(Freshness Update)

7.2.22.1. 上线时间:2011年11月3号

7.2.22.1.1. 受影响网站:Google官方帖子明确表示:更新鲜的内容会被更多展示在搜索结果中,尤其是最近的事件或热门话题、定期举办或发生的事件(如奥运会之类)、经常会更新的信息(如最新产品)。影响了35%的查询。
7.2.23. 熊猫更新(Panda Update)

7.2.23.1. 上线时间:2011年2月24号

7.2.23.1.1. 受影响网站:内容低质量的页面排名被降低,如转载、抄袭的内容,大量用户发的垃圾留言、主体内容太少、关键词堆积等等。
熊猫更新打击面大,影响大致12的查询结果,对现今SEO方法产生了重要影响。Panda算法最初是后台计算,集中上线,从2011年上线到2015年融入到核心算法中,经历了近30次更新。
熊猫算法更新最初被SearchEngineLand命名为Farmers Update,内容农场更新,后来Google自己公布了算法代码是Panda,和咱们的熊猫没关系,是Google内部开发此算法的主要工程师之一的名字叫Panda。
7.2.24. 采集惩罚算法(Scraper Algorithm)
7.2.24.1. 上线时间:2011年1月28号

7.2.24.1.1. 受影响网站:Matt Cutts的博客帖子公布的这个算法,采集、抄袭的内容页面被惩罚,奖励原出处。2%查询受影响。
7.2.25. 负面评价处理(Negative Review)

7.2.25.1. 上线时间:2010年12月1号
7.2.25.1.1. 受影响网站:这个算法是由于 Google的人读到纽约时报的一篇报道,一位顾客在某商家的体验很差,所以上网写了负面评论,但负面评论却给商家带来更多链接,链接又导致商家网站排名上升,带来更多生意。Google很快采取措施,检测这类负面评论,降低相应商家排名。
7.2.26. 咖啡因更新(Caffeine)
7.2.26.1. 上线时间:2010年6月1号
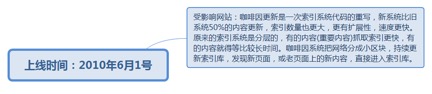
7.2.26.1.1. 受影响网站:咖啡因更新是一次索引系统代码的重写,新系统比旧系统50%的内容更新,索引数量也更大,更有扩展性,速度更快。原来的索引系统是分层的,有的内容(重要内容)抓取索引更快,有的内容就得等比较长时间。咖啡因系统把网络分成小区块,持续更新索引库,发现新页面,或老页面上的新内容,直接进入索引库。
7.2.27. Mayday Update
7.2.27.1. 上线时间:2010年4月28号-5月3号

7.2.27.1.1. 受影响网站:根据Matt Cutts的视频说明,Mayday更新主要针对长尾查询词,算法会寻找哪些网站的页面质量更符合要求。当然这种说明说了也是和没说差不多。SEO们的观察是,受影响的主要是大型网站上离首页点击距离比较远、没什么外链、内容没有什么附加价值的页面 — 很多电商网站的产品页面就是这样的,内容是供应商给的,也不大可能有外链。Mayday指的是发生在5月份,不是求救的那个Mayday。
7.2.28. 页面速度因素(Page Speed Ranking Factor)

7.2.28.1. 上线时间:2010年4月

7.2.28.1.1. 受影响网站:顾名思义,打开速度快的页面排名会给予提升,虽然幅度不大。速度的测量包括蜘蛛抓取时页面的反应速度和工具条记录的用户打开页面时间。2013年6月,Matt Cutts暗示,速度特别慢的页面可能会被惩罚,不过也不用特别担心,除非页面速度慢到一定程度。
7.2.29. Vince/品牌更新(Vince/Brand Update)

7.2.29.1. 上线时间:2009年2月1号

7.2.29.1.1. 受影响网站:大品牌网站页面在很多查询结果中(都是非长尾的大词)排名显著提高,所以最初被称为品牌更新。
7.2.30. Dewey Update
7.2.30.1. 上线时间:2008年3月

7.2.30.1.1. 受影响网站:不明,SEO行业观察到排名剧烈变动,但没有找到明显规律。Dewey这个名字的来源是因为Matt Cutts在 webmasterworld论坛里征求这次算法更新的反馈意见,站长需要在反馈中标明Dewey这个词,可能是Google内部的识别代码。
7.2.31. 大爸爸(Big Daddy)
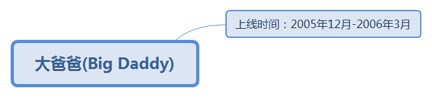
7.2.31.1. 上线时间:2005年12月-2006年3月

7.2.31.1.1. 大爸爸是一次Google算法基础架构的重写,解决了网址规范化、301/302转向等技术问题。大爸爸是一个数据中心一个数据中心更新的,不是同时上线的。
大爸爸这名字怎么来的?据Matt Cutts帖子说,2005年12月的Pubcon会议上,Matt Cutts征求大家对这次更新的反馈,Matt Cutts知道更新已经在一个数据中心上线了,所以问大家有什么好名字来指这个数据中心,一位站长说,叫BigDaddy吧,他孩子就这么叫他的,Matt Cutts觉得挺好,就叫这个名字了。
7.2.32. Jagger Update
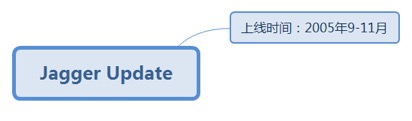
7.2.32.1. 上线时间:2005年9-11月

7.2.32.1.1. 受影响网站:Jagger分3个阶段上线,所以有Jagger1, Jagger2, Jagger3的名字。Jagger更新主要打击低质量链接,如交换链接、链接农场、买卖链接等。
7.2.33. Bourbon Update
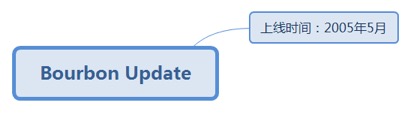
7.2.33.1. 上线时间:2005年5月

7.2.33.1.1. 受影响网站:早期Google更新往往没有官方信息,所以针对的是哪些网站经常不明,只是监测到排名有比较大变化。Bourbon一般认为与网址规范化有关。
7.2.34. Allegra Update
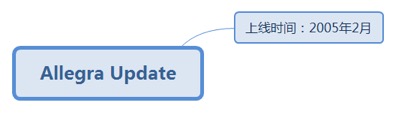
7.2.34.1. 上线时间:2005年2月

7.2.34.1.1. 受影响网站:不明确,或者说范围广泛,包括低质量外链、关键词堆积、过度优化等。
7.2.35. 公布支持nofollow
7.2.35.1. 上线时间:2005年1月

7.2.35.1.1. 现在SEO对nofollow肯定都很熟悉了,包括百度,所有主流搜索引擎都支持nofollow。还不知道的请参考以前关于nofollow的帖子。
7.2.36. Brandy Update
7.2.36.1. 上线时间:2004年2月

7.2.36.1.1. 受影响网站:链接锚文字作用提高,链接需要来自好邻居的概念第一次被提出来。索引库增长,抓取索引了很多新的链接,一些网站获得了更高权威度。
7.2.37. 弗罗里达更新(Florida Update)

7.2.37.1. 上线时间:2003年11月

7.2.37.1.1. 受影响网站:弗罗里达更新是早期最著名的Google算法更新,影响面大,受影响的以商业意图明显的词为主,一些靠搜索流量的小公司倒闭,有的SEO公司因此陷入困境,因为客户网站排名下降,不续费了。弗罗里达更新的后果大到,Google曾经承诺,以后不在年底上线这么大的更新了,以免剧烈影响很多商家的圣诞季销售业绩。
7.2.38. Update Fritz
7.2.38.1. 上线时间:2003年7月

7.2.38.1.1. Fritz更新是Google转为每天持续小幅更新索引的开始,这种更新方法又被称为everflux。Update Fritz这个名字是Matt Cutts在他2006年的博客帖子里提到的Google内部名称,不是webmasterworld命名系列里的。
7.2.39. Esmeralda Update
7.2.39.1. 上线时间:2003年6月1号

7.2.39.1.1. 这是早期每个月发生一次的Google Dance的最后一次。这次更新之后,Google算法更新改为小幅、持续性的,当然这是相对Google Dance每个月一次、持续数天、排名剧烈波动而言。准确地说,Google Dance是索引更新,不是算法更新。Esmeralda更新之后,Google就不再Dance了。
7.2.40. Dominic Update
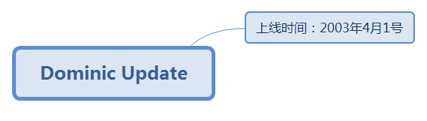
7.2.40.1. 上线时间:2003年4月1号

7.2.40.1.1. Brett Tabke和webmasterworld第一次特意给Google更新起名字。既然第一个名字是Boston,是个男名,这次应该是C打头的女名,大家投票,Cassandra胜出,没有其它特别意义。
7.2.41. Boston Update
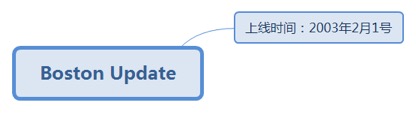
7.2.41.1. 上线时间:2003年2月1号

7.2.41.1.1. 2003年波士顿举行的SES大会上,Google员工公布了这次更新,为了和其它Google Dance以示区别,取名Boston。webmasterworld的创始人Brett Tabke就想,给更新取名字是个挺好的主意,所以就效仿台风的命名方法给Google更新取名,按字母排序,男名女名间隔,也得到了Google的首肯。所以早期的Google算法更新大多是webmasterworld命名的。
7.2.42. Google Dance

7.2.42.1.

7.2.42.1.1. 早期Google索引库每个月更新一次,是线下计算,然后集中上线。由于数据量大,需要一个数据中心一个数据中心地上线,不是同时上线的。在更新期间,用户这分钟访问的是一个数据中心,下一分钟可能访问的是另一个数据中心,看到的搜索结果可能有很大差别,因此被称为Google Dance。
7.3. 通用算法
7.3.1. 搜索结果时效性
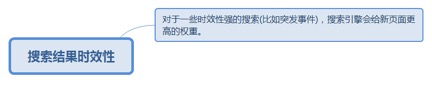
7.3.1.1. 对于一些时效性强的搜索(比如突发事件),搜索引擎会给新页面更高的权重。
7.3.2. 搜索结果多样性

7.3.2.1. 一些模糊搜索词比如“苹果”“大豆”,搜索引擎会给出多样性的搜索结果,因为这些词都用多种含义。
7.3.3. 用户浏览历史记录
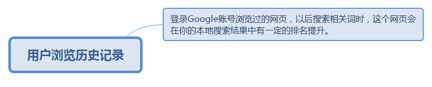
7.3.3.1. 登录Google账号浏览过的网页,以后搜索相关词时,这个网页会在你的本地搜索结果中有一定的排名提升。
7.3.4. 用户搜索历史

7.3.4.1. 你的搜索行为会影响以后的搜索结果。例如:如果你先搜索“评价”,然后搜索“烤面包机”,则Google更有可能在搜索结果中显示”烤面包机评价“。
7.3.5. 地理位置定位
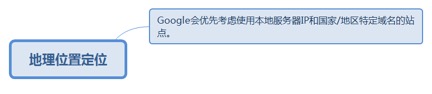
7.3.5.1. Google会优先考虑使用本地服务器IP和国家/地区特定域名的站点。
7.3.6. 安全搜索
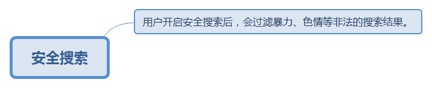
7.3.6.1. 用户开启安全搜索后,会过滤暴力、色情等非法的搜索结果。
7.3.7. Google+ 圈子

7.3.7.1. Google对你添加到Google+ 圈子的作者和网站显示更高的结果。
7.3.8. DMCA投诉

7.3.8.1. Google会降低收到DMCA投诉的页面权重。
7.3.9. 官方投放
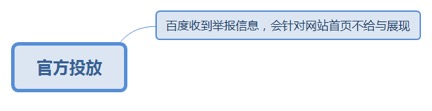
7.3.9.1. 百度收到举报信息,会针对网站首页不给与展现
7.3.10. 搜索结果的域名多样性

7.3.10.1. 谷歌2012年6月4日所谓的“大脚怪更新)”据说在每个SERP页面添加了更多域的页面结果。
7.3.11. 交易搜索
7.3.11.1. Google有时会针对有交易需求的关键字(如航班搜索)显示不同的展示结果。
7.3.12. 本地搜索
7.3.12.1. Google经常将Google plus的本地搜索结果放在“正常”SERP之上。
7.3.13. Google新闻框
7.3.13.1. 某些关键字可以触发Google新闻框样式,比如搜”the beatles(甲壳虫乐队)“。
7.3.14. 大品牌倾向
7.3.14.1. 在谷歌2009年的”Vince”算法更新后,开始让大品牌的一些短尾词搜索页面排名提升。
7.3.15. 购物结果

7.3.15.1. Google有时会在SERP中显示Google购物的结果
7.3.16. 图像结果
7.3.16.1. 搜索引擎有时会在搜索里显示一些图片搜索结果列表
7.3.17. 搜索彩蛋结果

7.3.17.1. 有些搜索结果会出现彩蛋结果,比如:Google有十几个复活节彩蛋结果。
7.3.18. 品牌词结果
7.3.18.1. 域名或品牌关键词会显示同一个网站的多个搜索结果。
8. SPAM(搜索引擎作弊)
8.1. 搜索引擎垃圾技术
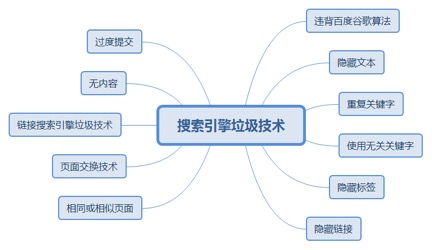
8.1.1. 违背百度谷歌算法
8.1.2. 隐藏文本

8.1.2.1. 利用文本与背景色的相同来达到隐藏关键字的目的。这样,用户是看不到这样字,不影响用户的正常阅读,但是搜索引擎却一目了然。这是一种最常用的搜索引擎垃圾技术。
8.1.3. 重复关键字

8.1.3.1. 经常与隐藏文本一起使用。但是这种做法会在页面的底部不断的以小号字重复关键字,或者把它隐藏在meta标签里面。这是最流行的搜索引擎垃圾技术。
8.1.4. 使用无关关键字

8.1.4.1. 从不在他们的网站中使用一些热门的关键字,而是使用一些与他们网站无关的关键字。这样,有些人用这些冷门的关键字进行搜索时就会找到他的网站。但是这样做是完全没有用的,当访问者发现这个网站不是他们想要的内容的时候,他们就会立即离开。这样做既欺骗了搜索引擎也欺骗了访问者。
8.1.5. 隐藏标签
8.1.5.1. 把关键字隐藏在html标签里面,如:style tags ,alt tags 等等。
8.1.6. 隐藏链接

8.1.6.1. 隐藏链接对一些搜索引擎来说也会被认为是搜索引擎垃圾技术,但另外一些则不是这样。
8.1.7. 相同或相似页面

8.1.7.1. 不要复制页面(或门户页面),或者给这些相同页面不同的名字然后又提交到搜索引擎中。这是搜索引擎跟分类目录都明显反对的。
8.1.8. 页面交换技术

8.1.8.1. 这是对搜索引擎访问时采用一个页面以提高在搜索引擎上的排名,而面对访问者的时候却采用另外一个页面。这样做也会在一时半刻得到不错的网站排名,但是后果是:一旦搜索引擎发现了,你的网站将会在他的数据库中永远除名。
8.1.9. 链接搜索引擎垃圾技术

8.1.9.1. 搜索引擎会认为那些通过自助链接系统建立的链接为搜索引擎垃圾技术。
8.1.10. 无内容

8.1.10.1. 网站没有专一的内容对于搜索者来说是垃圾网站。不合法的内容、复制的内容和那些全都是友情链接的网页,对于搜索引擎来说也是搜索引擎垃圾技术。
8.1.11. 过度提交

8.1.11.1. 每个搜索引擎都会限定一个网站提交网页的数量与提交的频率。在一个月之内不要向同一个搜索引擎提交多于一次(即只能提交一次),也不能向同一搜索引擎在一天之内提交多个页面。切记不要向他们提交门户页面。一定要根据搜索引擎的指导方针行事。
8.2. 站外SPAM
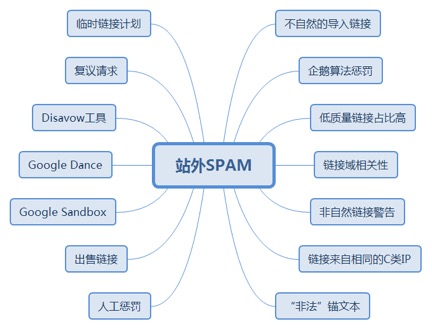
8.2.1. 不自然的导入链接

8.2.1.1. 突然(和不自然)的导入链接增加是虚假链接的特征标志
8.2.2. 企鹅算法惩罚
8.2.2.1. 被Google企鹅算法打击的网站,搜索可见性会变差。
8.2.3. 低质量链接占比高

8.2.3.1. 黑帽SEO通常使用大量博客评论或论坛链接,很容易识别出作弊。
8.2.4. 链接域相关性
8.2.4.1. 著名的分析MicroSiteMasters.com发现,Google企鹅算法对大量不自然、不相关网站的链接很敏感,有可能做出惩罚。
8.2.5. 非自然链接警告
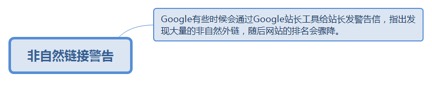
8.2.5.1. Google有些时候会通过Google站长工具给站长发警告信,指出发现大量的非自然外链,随后网站的排名会骤降。
8.2.6. 链接来自相同的C类IP
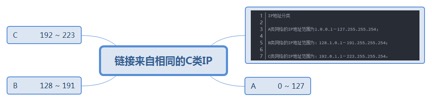
8.2.6.1.
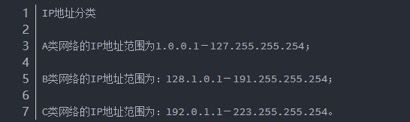
8.2.6.2. A 0 ~ 127
8.2.6.3. B 128 ~ 191
8.2.6.4. C 192 ~ 223
8.2.7. “非法”锚文本

8.2.7.1. 大量“非法”锚文本(比如处方药、博彩、小额贷款关键字)指向你的网站,无论哪种方式,都可能会损害你的网站排名。
8.2.8. 人工惩罚
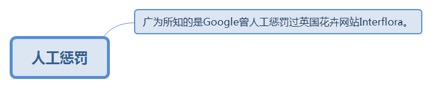
8.2.8.1. 广为所知的是Google曾人工惩罚过英国花卉网站Interflora。
8.2.9. 出售链接
8.2.9.1. 出售链接肯定会影响PageRank,从而伤害到网站的搜索可见性。
8.2.10. Google Sandbox

8.2.10.1. 新网站突然获得大量外链,一般会被Google放入Google沙盒中,这会影响网站的搜索可见性。
8.2.11. Google Dance

8.2.11.1. Google Dance会让排名浮动变化,根据Google专利,这可能是他们检查网站是否试图欺骗算法的一种方式。一个月一次数据库大更新
8.2.12. Disavow工具
8.2.12.1. 使用Google的“链接拒绝工具”可以消除负面SEO受害者网站的人工或算法惩罚。
8.2.13. 复议请求
8.2.13.1. 在Google站长工具里提交复议请求,如果成功可以解除惩罚。
8.2.14. 临时链接计划
8.2.14.1. Google显然可以识别先创建,然后再快速删除临时链接以避免惩罚的做法,也被称为临时链接方案。
8.3. 站外SPAM
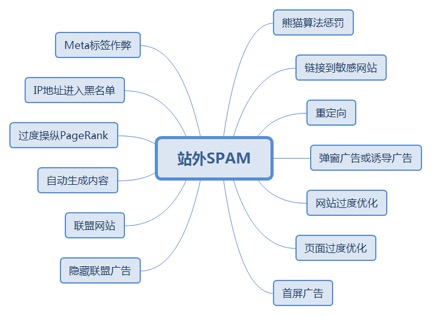
8.3.1. 熊猫算法惩罚
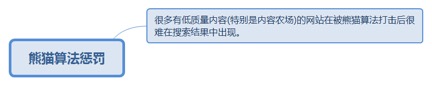
8.3.1.1. 很多有低质量内容(特别是内容农场)的网站在被熊猫算法打击后很难在搜索结果中出现。
8.3.2. 链接到敏感网站

8.3.2.1. 如果你的网站链接指向到一些敏感网站,像处方药或小额贷款网站,可能会影响你的网站搜索可见性。
8.3.3. 重定向
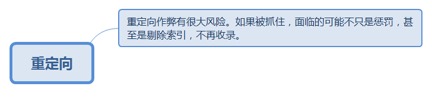
8.3.3.1. 重定向作弊有很大风险。如果被抓住,面临的可能不只是惩罚,甚至是剔除索引,不再收录。
8.3.4. 弹窗广告或诱导广告

8.3.4.1. Google网站评分指南指出:弹窗广告或诱导广告是低质量网站的标志。
8.3.5. 网站过度优化
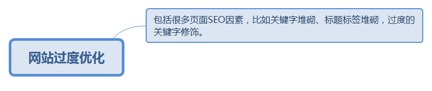
8.3.5.1. 包括很多页面SEO因素,比如关键字堆砌、标题标签堆砌,过度的关键字修饰。
8.3.6. 页面过度优化

8.3.6.1. 许多人反映说,企鹅算法不像熊猫算法那样,企鹅算法会针对具体页面(甚至仅针对特定关键字)处理。
8.3.7. 首屏广告
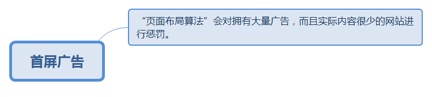
8.3.7.1. “页面布局算法”会对拥有大量广告,而且实际内容很少的网站进行惩罚。
8.3.8. 隐藏联盟广告

8.3.8.1. 当试图隐藏联盟链接(特别是隐藏)会带来惩罚。
8.3.9. 联盟网站
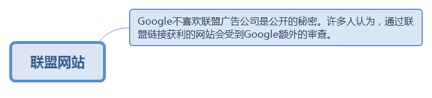
8.3.9.1. Google不喜欢联盟广告公司是公开的秘密。许多人认为,通过联盟链接获利的网站会受到Google额外的审查。
8.3.10. 自动生成内容

8.3.10.1. Google不喜欢自动生成内容的网站。如果Google怀疑你的网站靠机器自动生成内容,可能会导致惩罚或剔除索引(俗称拔毛)。
8.3.11. 过度操纵PageRank

8.3.11.1. 过度操纵PageRank可能会惩罚,比如把所有出站链接或大部分内链都加上Nofollow。
8.3.12. IP地址进入黑名单

8.3.12.1. 如果你的服务器IP地址被标记黑名单(比如大量发垃圾邮件),可能会影响服务器上的所有网站。
8.3.13. Meta标签作弊

8.3.13.1. 关键词堆砌也可能发生在Meta标记中。如果Google认为你通过Meta标签作弊,那么他们可能会惩罚你的网站。
9. 百度专利

9.1. 检索词核心权重确定方法和装置

9.1.1. 申请日:2009年12月18日

9.1.1.1. 本发明实施例提供一种检索词核心权重确定方法和装置,该检索词核心权重确定方法包括:在线下核心计算生成的第一词典文件中查找检索词;如果在第一词典文件中查找到所述检索词,则输出第一词典文件对应的第一数据文件中保存的与检索词对应的核心权重;如果在第一词典文件中未查找到检索词,则对检索词进行处理,并在第一词典文件中查找处理后的检索词,如果查找到处理后的检索词,则输出第一词典文件对应的第一数据文件中保存的与处理后的检索词对应的核心权重;如果在第一词典文件中未查找到处理后的检索词,则对处理后的检索词进行切词计算,获得处理后的检索词的核心权重。本发明实施例实现了提高核心权重的准确度,进而提高了核心分析的效果。

9.1.1.1.1. <u>http://www.soopat.com/Patent/200910242875</u>
9.2. 点击有效性的判断方法及其系统

9.2.1. 申请日:2010年6月18日

9.2.1.1. 提供了一种点击有效性的判断方法,包括:当广告主登陆推广平台时,记录广告主的相关信息;当发布商登陆后台系统时,记录发布商的相关信息;获取搜索引擎的联盟站点的服务器信息并进行记录;关于对广告的每次点击,获取该点击来源的相关信息,该相关信息包括点击来源的IP、Cookie信息;将所述点击来源的相关信息与广告主的相关信息、发布商的相关信息和服务器信息进行比较,以判断所述点击的有效性。

9.2.1.1.1. <u>http://www.soopat.com/Patent/201010210709</u>
9.3. 一种网页分块的重要度评估方法和设备

9.3.1. 申请日:2010年8月19日

9.3.1.1. 本发明提供一种网页分块的重要度评估方法和设备。其中该方法包括以下步骤:识别网页分块所在网页的类型以及所述网页分块的类型;根据所述网页的类型、所述网页分块的类型以及所述网页分块的属性,确定所述网页分块的权重值;对所述网页内的所述网页分块的权重值进行排序。本发明的优点是,根据网页的类型、网页分块的类型以及网页分块的属性,更为准确地确定网页分块的权重值,然后根据权重值对网页分块进行展开或者折叠,使网页适合于移动终端显示,便于用户浏览。

9.3.1.1.1. <u>http://www.soopat.com/Patent/201010256704</u>
9.4. 一种在网络设备中用于确定关键子词权重的方法和设备

9.4.1. 申请日:2010年10月9日

9.4.1.1. 获取来自用户的长尾关键词,根据第一预定规则并基于关联关键词来确定所述长尾关键词所包含的多个关键子词的权重
9.5. 用于确定字符串信息间相似度信息的方法、装置和设备

9.5.1. 申请日:2011年04月20日

9.5.1.1. 本发明的目的在于提供一种计算机实现的用于确定字符串信息间相似度信息的方案,该方案包括:获取待处理的两个字符串信息;根据将其中一个字符串信息转换至另一个字符串信息的转换处理中所执行编辑操作相关的字符变化信息,来确定所述两个字符串信息间的相似度信息。本发明不仅能够反映两个字符串信息间字形上的相似度,还能够进一步反映两个字符串信息间在词义、输入错误可能性、读音等方面的相似度,提高了字符串相似度判断的准确性;并且本发明通过采用历史操作代价,大幅减少相似度确定装置的资源消耗,能够更快获得两个字符串信息间的相似度信息。

9.5.1.1.1. <u>http://www.soopat.com/Patent/201110099425?lx=FMSQ</u>
9.6. 基于页面的预置链接关系确定页面权威值的方法与设备

9.6.1. 申请日:2010年12月31日
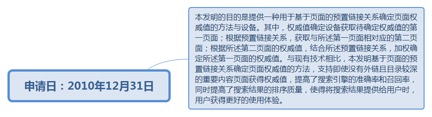
9.6.1.1. 本发明的目的是提供一种用于基于页面的预置链接关系确定页面权威值的方法与设备。其中,权威值确定设备获取待确定权威值的第一页面;根据预置链接关系,获取与所述第一页面相对应的第二页面;根据所述第二页面的权威值,结合所述预置链接关系,加权确定所述第一页面的权威值。与现有技术相比,本发明基于页面的预置链接关系确定页面权威值的方法,支持即使没有外链且目录较深的重要内容页面获得权威值,提高了搜索引擎的准确率和召回率,同时提高了搜索结果的排序质量,使得将搜索结果提供给用户时,用户获得更好的使用体验。

9.6.1.1.1. <u>http://www.soopat.com/Patent/201010620489?lx=FMSQ</u>
9.7. 一种用于确定超链接的锚文本可信度的分析设备和方法

9.7.1. 申请日:2010年12月31日

9.7.1.1. 本发明提供一种用于确定超链接的锚文本可信度的分析设备和方法,包括:获取与所述超链接相对应的锚文本;根据所述锚文本,获取与所述锚文本对应的锚文本相关信息;根据所述锚文本相关信息,加权确定所述超链接的锚文本可信度。与现有技术相比,本发明基于锚文本相关信息来加权确定超链接的锚文本可信度,使超链接的锚文本与超链接指向页面之间的内容相关性更加合理。此外,将本发明应用到搜索引擎领域,还可精确地检测作弊超链的虚假锚文本、过期超链的失效锚文本,调整基于所述虚假锚文本和失效锚文本的页面权威度和排名,进而提升搜索引擎搜索结果的排序质量。

9.7.1.1.1. <u>http://www.soopat.com/Patent/201010620489?lx=FMSQ</u>
9.8. 挖掘相关实体词的关系关键词的方法和装置及其应用

9.8.1. 申请日:2011年3月28日

9.8.1.1. 本发明提供了一种挖掘相关实体词的关系关键词的方法和装置及其应用,其中挖掘关系关键词的方法包括:挖掘实体词e1的相关实体词e2,将所述e1及其相关实体词e2存储在数据库中;在挖掘所述e2所使用的资源,和/或,在由所述e1和所述e2构成一个搜索请求(query)所对应的搜索结果中,对距离所述e1和所述e2设定距离范围内的各词语进行统计,所述统计至少包括:对所述各词语在所述距离范围内出现次数的统计;利用统计结果对所述各词语进行打分,选择打分值排在前M个的词语作为所述e1和所述e2的关系关键词,并将所述关系关键词记录在所述数据库中。通过本发明确定的关系关键词能够根据文本实际情况描述出任何实体词之间的关系,从而提高了实体词之间关系描述的准确性。

9.8.1.1.1. <u>http://www.soopat.com/Patent/201110075248?lx=FMSQ</u>
9.9. 基于非线性统一权值对检索结果进行排序的方法及装置

9.9.1. 申请日:2011年3月28日

9.9.1.1. 本发明涉及互联网信息处理领域,特别涉及一种基于非线性统一权值对检索结果进行排序的方法及装置,用于提高搜索引擎的检索结果排序的精准性。该方法为:根据用户输入的检索关键词获得对应的检索结果;分别计算每一个检索结果的非线性统一权值,所述非线性统一权值表征为,其中,w表示检索结果与检索关键词之间的相关性,u表示除相关性之外预设的各参数的加权幅度之和;根据每一个检索结果的非线性统一权值,对各检索结果进行排序。这样,便提高了搜索引擎获得的各url的排序精准性,令用户可以迅速获得符合自身需求的url,从而有效提高了搜索引擎的检索性能,提升了搜索引擎的检索效率。

9.9.1.1.1. <u>http://www.soopat.com/Patent/201110075248?lx=FMSQ</u>
9.10. 确定站点的领域信息以及相关性判定方法、系统及设备-公开

9.10.1. 申请日:2011年5月9日

9.10.1.1. 本发明公开了一种确定站点的领域信息以及相关性判定方法、系统及设备,主要内容包括:针对站点内的每一页面,确定该页面相对于预设的多个主题中每个主题的似然度,并根据每个页面对于各主题的似然度来表示页面所属站点的主题分布,进而来确定站点对应的领域信息,由于预设的主题数量可以很高,因此,根据站点内各页面与每个预设的主题之间的似然度关系确定的页面所表示的主题数量可以是海量的,使得最终确定的站点对应的领域信息是细粒度、准确的领域信息,进而提高利用领域信息对站点之间、站点与页面之间相关性判定的准确性。

9.10.1.1.1. <u>http://www.soopat.com/Patent/201110118083?lx=FMSQ</u>
9.11. 一种用于确定图片相似度的方法与设备

9.11.1. 申请日:2011年6月28日

9.11.1.1. 本发明的目的是提供一种用于确定图片相似度的方法与设备。其中,相似度确定设备从图片索引库中获取与查询关键词相对应的图片;获取所述图片中的用户点击图片;根据所述用户点击图片,获取与所述查询关键词相对应的视觉需求信息;根据所述视觉需求信息,确定所述图片与所述视觉需求信息相对应的图片相似度。本发明使得图片搜索引擎等图片检索设备在提供相应图片搜索结果时,可以根据这些图片搜索结果与用户点击图片的图片相似度进行排序。由于图片相似度是根据特定查询关键词所对应的每个图片的图片特征信息与该特定查询关键词所对应的用户点击图片的视觉需求信息得到的,故该图片相似度兼顾了用户的查询需求以及视觉需求。

9.11.1.1.1. <u>http://www.soopat.com/Patent/201110180020</u>
9.12. 建立需求分析模板的方法、搜索需求识别的

9.12.1. 申请日:2011年9月9日

9.12.1.1. 本发明提供了一种建立需求分析模板的方法、搜索需求识别的方法及装置,其中建立需求分析模板的方法包括:获取需求类型的种子query集合;确定种子query集合的所有n元词组(n-gram),n为预设的一个或多个正整数;根据统计得到的各n-gram在需求类型的种子集合中的出现次数,将种子query集合的各种子query中N1个出现次数最低的n-gram替换为通配符,得到候选需求分析模板,N1为预设的正整数;对各候选需求分析模板进行置信度评分,选择置信度评分排在前N2个的候选需求分析模板作为需求类型的需求分析模板,N2为预设的正整数。通过本发明能够节约人力成本,扩大适用面以及提高召回率和识别准确率。
9.13. 一种挖掘具有相似需求的查询的方法及装置

9.13.1. 申请日:2011年11月23日
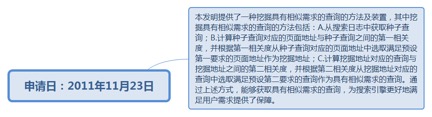
9.13.1.1. 本发明提供了一种挖掘具有相似需求的查询的方法及装置,其中挖掘具有相似需求的查询的方法包括:A.从搜索日志中获取种子查询;B.计算种子查询对应的页面地址与种子查询之间的第一相关度,并根据第一相关度从种子查询对应的页面地址中选取满足预设第一要求的页面地址作为挖掘地址;C.计算挖掘地址对应的查询与挖掘地址之间的第二相关度,并根据第二相关度从挖掘地址对应的查询中选取满足预设第二要求的查询作为具有相似需求的查询。通过上述方式,能够获取具有相似需求的查询,为搜索引擎更好地满足用户需求提供了保障。

9.13.1.1.1. <u>http://www.soopat.com/Patent/201110376378</u>
9.14. 一种挖掘具有相似需求的查询的方法及装置

9.14.1. 申请日:2011年11月24日
9.14.1.1. 本发明提供了一种挖掘具有相似需求的查询的方法及装置,其中挖掘具有相似需求的查询的方法包括:为多个查询对提取会话共现特征、点击重合度特征或点击相互满足特征中的至少一个特征;根据提取的每个特征及每个特征的权重计算各查询对中的两个查询之间的相似度;选取两个查询之间的相似度大于设定值的查询对,并在选取的查询对中将相互之间有交集的查询对聚为一类,将属于同一类的查询对中的查询作为具有相似需求的查询。通过上述方式,可以从搜索日志中挖掘出具有相似需求的查询,从而为搜索引擎更好地满足用户需求提供了保障。

9.14.1.1.1. <u>http://www.soopat.com/Patent/201110379429?lx=FMSQ</u>
9.15. 一种应用的泛需求检索方法及系统

9.15.1. 申请日:2013年2月22日
9.15.1.1. 本发明提供了一种应用的泛需求检索方法及系统,该方法包括:对泛需求检索的查询词进行解析,得到所述查询词的概念标签或属性标签;所述概念标签和属性标签分别描述应用的类别和属性;依据所述查询词的概念标签或属性标签在预设的应用标签体系中进行匹配,得到包含所述概念标签或属性标签的应用;依据所述查询词的概念标签或属性标签获得所述应用的相关性分数,并依据相关性分数对应用进行排序,将排序后的应用作为查询词的检索结果提供给用户。根据本发明提供的技术方案,能够提高泛需求检索场景中检索结果的多样性和相关性。

9.15.1.1.1. <u>http://www.soopat.com/Patent/201310056283?lx=FMSQ</u>
9.16. 得到和搜索结构化语义知识的方法及对应

9.16.1. 申请日:2011年12月28日
9.16.1.1. 本发明提供了一种得到和搜索结构化语义知识的方法及对应装置,从已有语料中抽取出实体类型E的实体ei;从搜索日志中获取所有包含E的搜索项(query),从query中E之前出现的实词抽取候选需求限定词dm,构成候选需求限定词集合{dm};从大规模语料库中抽取出包含属于E的ei且包含{dm}中至少一个候选需求限定词的句子,从句子中选择出现次数满足第二出现次数要求的候选需求限定词作为需求限定词cj,确定所抽取句子中cj和ei构成的词语对< cj,ei> ;将< cj,ei> 存入实体类型E对应的结构化数据库。获取到用户输入的包含需求限定词c和实体类型E的query时,从所述EKBase中搜索所述c对应的所有实体e并包含在搜索结果中返回给用户。

9.16.1.1.1. <u>http://www.soopat.com/Patent/201110447926?lx=FMSQ</u>
9.17. 原创内容的搜索方法和搜索服务器

9.17.1. 申请日:2013年04月27日

9.17.1.1. 本发明提出一种原创内容的搜索方法和搜索服务器,其中方法包括:搜索服务器接收客户端发送的搜索词;搜索服务器根据搜索词获得N个搜索结果,N为大于1的正整数;搜索服务器对N个搜索结果进行分析以确定N个搜索结果中的M个原创内容发布源,其中,M为正整数且小于N;以及搜索服务器对M个原创内容发布源进行特殊标记之后并提供至客户端。根据本发明实施例的方法,通过对搜索结果进行分析获取搜索结果中的原创内容发布源,并对原创内容发布源进行特殊标记后提供至客户端,能够为用户提供高质量的原创内容,并充分体现了原创内容的价值,同时有效的保护了原创内容作者的权益,有利于互联网知识产权保护的发展。

9.17.1.1.1. <u>http://www.soopat.com/Patent/201310153664?lx=FMSQ</u>
9.18. 搜索候选词的推荐方法及搜索引擎

9.18.1. 申请日:2013年5月7日
9.18.1.1. 本发明提出一种搜索候选词的推荐方法及搜索引擎,其中所述方法包括:搜索引擎服务器接收用户输入的输入信息,并获得输入信息的前缀信息;将前缀信息作为索引获得多个搜索候选词以及每个搜索候选词的权重;判断多个搜索候选词中是否存在至少两个搜索候选词属于同一主题;如果判断存在至少两个搜索候选词属于同一主题,则保留至少两个搜索候选词中的一个搜索候选词的权重不变,对至少两个搜索候选词中的其他搜索候选词的权重进行降权处理;以及根据多个搜索候选词的权重进行排序,将排序之后的搜索候选词提供至用户。根据本发明实施例的方法,提高了搜索候选词的多样性和准确性,能够满足用户的搜索需求,并且算法简单,易于实施,提升用户体验。

9.18.1.1.1. <u>http://www.soopat.com/Patent/201310165048?lx=FMSQ</u>
9.19. 生成共现关键词的方法、提供关联搜索词的方法以及系统

9.19.1. 申请日:2013年5月8日
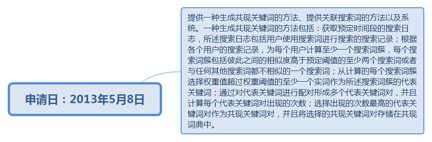
9.19.1.1. 提供一种生成共现关键词的方法、提供关联搜索词的方法以及系统。一种生成共现关键词的方法包括:获取预定时间段的搜索日志,所述搜索日志包括用户使用搜索词进行搜索的搜索记录;根据各个用户的搜索记录,为每个用户计算至少一个搜索词簇,每个搜索词簇包括彼此之间的相似度高于预定阈值的至少两个搜索词或者与任何其他搜索词都不相似的一个搜索词;从计算的每个搜索词簇选择权重值超过权重阈值的至少一个实词作为所述搜索词簇的代表关键词;通过对代表关键词进行配对形成多个代表关键词对,并且计算每个代表关键词对出现的次数;选择出现的次数最高的代表关键词对作为共现关键词对,并且将选择的共现关键词对存储在共现词典中。

9.19.1.1.1. <u>http://www.soopat.com/Patent/201310165690?lx=FMSQ</u>
9.20. 搜索引擎中相关性策略之间耦合度的分析方法及装置

9.20.1. 申请日:2013年6月4日

9.20.1.1. 本发明提出一种搜索引擎中相关性策略之间耦合度的分析方法及装置,其中所述方法包括:获取搜索引擎中的相关性策略集合;对多个相关性策略进行分析以确定每个相关性策略中的策略生效位置;在每个相关性策略中的策略生效位置分别插入探针函数及每个策略生效位置对应的策略标识;以及向搜索引擎输入至少一个搜索词并根据搜索引擎输出的策略路径文件进行耦合度分析,其中,策略路径文件包括搜索引擎为至少一个搜索词调用的相关性策略所对应的策略标识。根据本发明实施例的方法,能够灵活控制耦合度分析的粗细粒度,且对搜索模块影响小,成本低,对相关性策略定位准确、迅速,提高了耦合度分析效率。

9.20.1.1.1. <u>http://www.soopat.com/Patent/201310219735?lx=FMSQ</u>
9.21. 一种搜索结果的生成方法和装置

9.21.1. 申请日:2012年02月23日
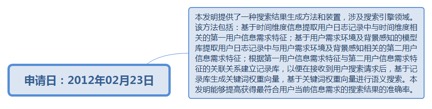
9.21.1.1. 本发明提供了一种搜索结果生成方法和装置,涉及搜索引擎领域。该方法包括:基于时间维度信息提取用户日志记录中与时间维度相关的第一用户信息需求特征;基于用户需求环境及背景感知的模型库提取用户日志记录中与用户需求环境及背景感知相关的第二用户信息需求特征;根据第一用户信息需求特征与第二用户信息需求特征的关联关系建立记录库,以便在接收到用户搜索请求后,基于记录库生成关键词权重向量,基于关键词权重向量进行语义搜索。本发明能够提高获得最符合用户当前信息需求的搜索结果的准确率。

9.21.1.1.1. <u>http://www.soopat.com/Patent/201711468186</u>
9.22. 一种用于获取页面相似度的方法与设备

9.22.1. 申请日:2012年03月29日

9.22.1.1. 本发明的目的是提供一种用于获取页面相似度的方法与设备。本发明中首先确定一个页面中的一个或多个页面块与另一页面中的一个或多个页面块之间的块相似度,接着根据两个页面中各个页面块的权重及其块相似度,加权确定该两个页面的页面相似度,从而将页面块的权重引入页面相似度判定标准中,通过对不同页面块的准确赋权,体现出不同页面块的价值差异,从而获得更为准确的页面相似度判定结果,进一步为保证较高的过滤重复网页准确性提供了保证。

9.22.1.1.1. <u>http://www.soopat.com/Patent/201210089360?lx=FMSQ</u>
9.23. 提取关键词的方法和设备
9.23.1. 申请日:2013年11月29日
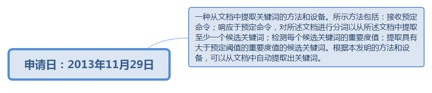
9.23.1.1. 一种从文档中提取关键词的方法和设备。所示方法包括:接收预定命令;响应于预定命令,对所述文档进行分词以从所述文档中提取至少一个候选关键词;检测每个候选关键词的重要度值;提取具有大于预定阈值的重要度值的候选关键词。根据本发明的方法和设备,可以从文档中自动提取出关键词。
9.23.1.1.1. <u>http://www.soopat.com/Patent/201310627998</u>
9.24. 一种根据海量数据进行应用相似度判断的方法及系统

9.24.1. 申请日:2012年07月10日
9.24.1.1. 本发明提供一种根据海量数据进行应用相似度判断的方法,包括步骤:获取至少两个用户对至少两个应用的评分;根据所述评分生成评分矩阵;根据Map-Reduce模型计算所述矩阵中任意两个应用的相似度。相应的,本发明还提供一种根据海量数据进行应用相似度判断的系统,包括:获取装置,用于获取至少两个用户对至少两个应用的评分;生成装置,用于根据所述评分生成评分矩阵;计算装置,用于根据Map-Reduce模型计算所述矩阵中任意两个应用的相似度。本发明可以高效准确地获得应用相似度结果。

9.24.1.1.1. <u>http://www.soopat.com/Patent/201210238193</u>
9.25. 一种评估网页权威性的方法及装置

9.25.1. 申请日:2012年08月31日

9.25.1.1. 本发明提供了一种评估网页权威性的方法及装置,其中评估网页权威性的方法包括:获取网站间存在链接关系的网页作为第一网页集合,以及,获取网站内存在链接关系的网页作为第二网页集合;确定所述第一网页集合中各网页的外部权威性;将所述第一网页集合与所述第二网页集合中的交叉网页所具有的外部权威性传递至所述第二网页集合中的非交叉网页,以得到所述非交叉网页的外部权威性。通过上述方式,本发明可以大大提高对网页进行权威性评估时的准确性。

9.25.1.1.1. <u>http://www.soopat.com/Patent/201210320005?lx=FMSQ</u>
9.26. 基于关键词进行检索的方法及装置

9.26.1. 申请日:2013年12月20日
9.26.1.1. 本发明公开了基于关键词进行检索的方法及装置。该方法包括:根据文档库中基础关键词的预测权重确定检索请求中的候选关键词,其中所述关键词的预测权重是根据基础关键词在文档库的文档中的结构信息确定的;根据所述候选关键词在所述文档库中所属的主题,确定其他扩展关键词;根据候选关键词和扩展关键词在所述文档库中进行检索。本发明提出的技术方案能够提高检索结果的准确率和召回率,更符合用户需求。

9.26.1.1.1. <u>http://www.soopat.com/Patent/201310710834</u>
9.27. 一种网站重点页面的挖掘方法及装置

9.27.1. 申请日:2012年09月29日
9.27.1.1. 本发明提供了一种网站重点页面的挖掘方法及装置。其中网站重点页面的挖掘方法包括:分别从网站的各网页中提取导航链接串;分别将提取的各导航链接串拆分为链接对,其中每个链接对由该导航链接串中相邻位置的两个链接构成;从各链接对中确定重点链接对,并将所述重点链接对所对应的页面作为所述网站的重点页面。通过上述方式,本发明可以提高对网站重点页面进行挖掘时的召回率及准确率。

9.27.1.1.1. <u>http://www.soopat.com/Patent/201210380363?lx=FMSQ</u>
9.28. 一种提取领域关键词的方法及装置

9.28.1. 申请日:2014年03月19日
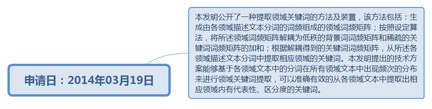
9.28.1.1. 本发明公开了一种提取领域关键词的方法及装置,该方法包括:生成由各领域描述文本分词的词频组成的领域词频矩阵;按照设定算法,将所述领域词频矩阵解耦为低秩的背景词词频矩阵和稀疏的关键词词频矩阵的加和;根据解耦得到的关键词词频矩阵,从所述各领域描述文本分词中提取相应领域的关键词。本发明提出的技术方案能够基于各领域文本中的分词在所有领域文本中出现频次的分布来进行领域关键词提取,可以准确有效的从各领域文本中提取出相应领域内有代表性、区分度的关键词。

9.28.1.1.1. <u>http://www.soopat.com/Patent/201410101751?lx=FMSQ</u>
9.29. 一种寻址类查询词的挖掘方法及系统

9.29.1. 申请日:2012年12月11日
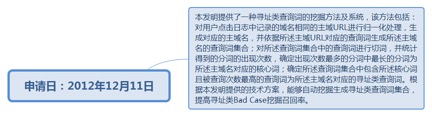
9.29.1.1. 本发明提供了一种寻址类查询词的挖掘方法及系统,该方法包括:对用户点击日志中记录的域名相同的主域URL进行归一化处理,生成对应的主域名,并依据所述主域URL对应的查询词生成所述主域名的查询词集合;对所述查询词集合中的查询词进行切词,并统计得到的分词的出现次数,确定出现次数最多的分词中最长的分词为所述主域名对应的核心词;确定所述查询词集合中包含所述核心词且被查询次数最高的查询词为所述主域名对应的寻址类查询词。根据本发明提供的技术方案,能够自动挖掘生成寻址类查询词集合,提高寻址类Bad Case挖掘召回率。

9.29.1.1.1. <u>http://www.soopat.com/Patent/201210533948?lx=FMSQ</u>
9.30. 一种用于确定页面中的垃圾文本信息的方法与设备

9.30.1. 申请日:2014年02月20日

9.30.1.1. 本发明的目的是提供一种用于确定页面中的垃圾文本信息的方法与设备。具体地,获取待处理的初始页面;确定初始页面所对应的一个或多个候选垃圾文本信息;确定候选垃圾文本信息所对应的作弊度信息;根据作弊度信息,从一个或多个候选垃圾文本信息中确定初始页面所对应的一个或多个垃圾文本信息。其中,与现有技术相比,本发明通过确定初始页面所对应的候选垃圾文本信息的作弊度信息,以根据作弊度信息,从候选垃圾文本信息中确定初始页面所对应的垃圾文本信息,实现了根据作弊度信息对候选垃圾文本信息进行筛选,有效地识别出初始页面中的垃圾文本信息,不仅提高了用户获取信息的安全性及获取信息的效率,相应地,也提升了用户搜索浏览体验。

9.30.1.1.1. <u>http://www.soopat.com/Patent/201410058591</u>
9.31. 确定目标关键词所对应的搜索相关性类别的方法和设备

9.31.1. 申请日:2012年12月27日

9.31.1.1. 本发明的目的是提供一种用于确定目标关键词所对应的搜索相关性类别的方法和设备。具体地,根据目标关键词的搜索排序路径信息,从一个或多个关键词聚类中确定所述目标关键词所属的目标关键词聚类;根据所述目标关键词聚类,确定所述目标关键词所对应的搜索相关性类别,以用于后续处理。与现有技术相比,本发明通过确定目标关键词所属的目标关键词聚类,进而所述目标关键词所对应的搜索相关性类别,以用于后续处理,从而实现了有效地确定关键词所对应的搜索相关性类别,及对批量关键词数据的自动化测试,不仅为优化搜索引擎搜索排序提供参考,而且提高了对搜索引擎相关性的测试效率。

9.31.1.1.1. <u>http://www.soopat.com/Patent/201210581476?lx=FMSQ</u>
9.32. 一种识别垃圾信息的方法与装置

9.32.1. 申请日:2014年4月1日

9.32.1.1. 本发明的目的是提供一种识别垃圾信息的方法与装置。其中,本发明通过将已识别信息和待识别信息提供给用户来进行垃圾信息判断,并根据其中每个用户判断垃圾信息的准确率来确定待识别信息是否属于垃圾信息。根据本发明的方案,其一方面可以解决采用单纯的技术手段不能全面识别垃圾信息的问题,以提供更加纯净的网络环境,提升用户的使用体验;另一方面,可以使得企业不再需要雇佣审查专员来进行垃圾信息识别的工作,降低了企业成本,同时提高了垃圾信息的识别效率。进一步地,本发明通过确定用户对已识别信息进行垃圾信息判断的准确率,还可以解决一部分用户误判的问题,提升整体判断待识别信息是否属于垃圾信息的准确度。

9.32.1.1.1. <u>http://www.soopat.com/Patent/201410128835</u>
9.33. 生成关联关键词、提供关联关键词的方法及系统

9.33.1. 申请日:2014年09月24日

9.33.1.1. 本发明提供一种生成关联关键词、提供关联关键词的方法及系统。所述生成关联关键词的方法包括:基于搜索日志选取具备预定的搜索行为特征的至少一个初选搜索词;根据所述初选搜索词,从包括多个关键词的关键词匹配信息选取至少一个与所述初选搜索词在类别上相关的关联关键词;将所述初选搜索词以及所述关联关键词存储在关联关键词词典中。所述生成关联关键词、提供关联关键词的方法及系统为指定类目下的搜索词选取在类别上相关的关联关键词,从而当接收到包括所述搜索词的搜索请求时,可将所述关联关键词提供给用户,为用户提供上下级类别的推荐条目。

9.33.1.1.1. <u>http://www.soopat.com/Patent/201410494326?lx=FMSQ</u>
9.34. 查询语句与网页相似度的确定方法、装置、终端及服务器

9.34.1. 申请日:2014年10月29日

9.34.1.1. 本发明实施例公开了查询语句与网页相似度的确定方法、装置、终端及服务器。该方法包括:通过预先创建的短语翻译模型,将目标查询语句翻译为具有相似语义的至少一条候选语句;根据所述至少一条候选语句与网页主题句之间的相似度,确定目标查询语句和网页主题句之间的相似度;其中,所述网页主题句为网页标题,或者基于设定算法对网页内容进行解析得到的用于描述网页主要内容的语句。本实施例提供的技术方案,可以提高搜索引擎对任一查询语句的网页召回率,使得搜索引擎能够针对表现形式不同而语义相似的各条查询句,返回相差较小的网页集合,提升用户对查询结果的满意度。

9.34.1.1.1. <u>http://www.soopat.com/Patent/201410592231</u>
9.35. 网页打分模型的创建方法及装置

9.35.1. 申请日:2014年11月06日
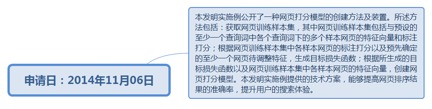
9.35.1.1. 本发明实施例公开了一种网页打分模型的创建方法及装置。所述方法包括:获取网页训练样本集,其中网页训练样本集包括与预设的至少一个查询词中各个查询词下的多个样本网页的特征向量和标注打分;根据网页训练样本集中各样本网页的标注打分以及预先确定的至少一个网页待调整特征,生成目标损失函数;根据所生成的目标损失函数以及网页训练样本集中各样本网页的特征向量,创建网页打分模型。本发明实施例提供的技术方案,能够提高网页排序结果的准确率,提升用户的搜索体验。

9.35.1.1.1. <u>http://www.soopat.com/Patent/201410638360?lx=FMSQ</u>
9.36. 确定短文本相似度的方法和装置

9.36.1. 申请日:2014年11月11日
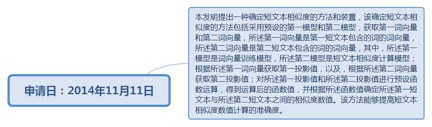
9.36.1.1. 本发明提出一种确定短文本相似度的方法和装置,该确定短文本相似度的方法包括采用预设的第一模型和第二模型,获取第一词向量和第二词向量,所述第一词向量是第一短文本包含的词的词向量,所述第二词向量是第二短文本包含的词的词向量,其中,所述第一模型是词向量训练模型,所述第二模型是短文本相似度计算模型;根据所述第一词向量获取第一投影值,以及,根据所述第二词向量获取第二投影值;对所述第一投影值和所述第二投影值进行预设函数运算,得到运算后的函数值,并根据所述函数值确定所述第一短文本与所述第二短文本之间的相似度数值。该方法能够提高短文本相似度数值计算的准确度。

9.36.1.1.1. <u>http://www.soopat.com/Patent/201410645486?lx=FMSQ</u>
9.37. 作弊文本的识别方法和系统
9.37.1. 申请日:2014年11月13日
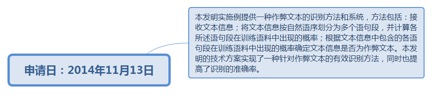
9.37.1.1. 本发明实施例提供一种作弊文本的识别方法和系统,方法包括:接收文本信息;将文本信息按自然语序划分为多个语句段,并计算各所述语句段在训练语料中出现的概率;根据文本信息中包含的各语句段在训练语料中出现的概率确定文本信息是否为作弊文本。本发明的技术方案实现了一种针对作弊文本的有效识别方法,同时也提高了识别的准确率。

9.37.1.1.1. <u>http://www.soopat.com/Patent/201410641811</u>
9.38. 通过计算机实现的计算文本相似度和搜索处理方法及装置

9.38.1. 申请日:2014年12月03日
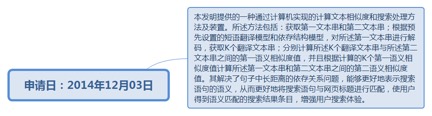
9.38.1.1. 本发明提供的一种通过计算机实现的计算文本相似度和搜索处理方法及装置。所述方法包括:获取第一文本串和第二文本串;根据预先设置的短语翻译模型和依存结构模型,对所述第一文本串进行解码,获取K个翻译文本串;分别计算所述K个翻译文本串与所述第二文本串之间的第一语义相似度值,并且根据计算的K个第一语义相似度值计算所述第一文本串和第二文本串之间的第二语义相似度值。其解决了句子中长距离的依存关系问题,能够更好地表示搜索语句的语义,从而更好地将搜索语句与网页标题进行匹配,使用户得到语义匹配的搜索结果条目,增强用户搜索体验。

9.38.1.1.1. <u>http://www.soopat.com/Patent/201410728432?lx=FMSQ</u>
9.39. 语义相似度计算方法、搜索结果处理方法和装置

9.39.1. 申请日:2014年12月02日

9.39.1.1. 本发明实施例提供了一种语义相似度计算方法、搜索结果处理方法和装置。所述语义相似度计算方法包括:获取第一文本串和第二文本串;分别对所述第一文本串和所述第二文本串进行分词,生成分词结果;根据所述分词结果分别将所述第一文本串和所述第二文本串分得的分词生成预定多个语义层;将所述第一文本串的每个语义层都分别与所述第二文本串的所有语义层进行依存相似度计算得到N×N个依存相似度值;根据计算的N×N个依存相似度值计算所述第一文本串和所述第二文本串的语义相似度值。通过本发明实施例的语义相似度计算方法、搜索结果处理方法和装置,能够提高文本串之间语义相似度计算的准确性。

9.39.1.1.1. <u>http://www.soopat.com/Patent/201410721307?lx=FMSQ</u>
9.40. 语句相似度的计算、搜索处理方法及装置

9.40.1. 申请日:2014年12月02日

9.40.1.1. 本发明提供一种通过计算机实现的语句相似度的计算、搜索处理方法及装置,上述计算方法包括:获取第一语句和第二语句;分别对第一语句和第二语句进行依存分析,得到第一依存树以及第二依存树;根据所述第一依存树以及第二依存树计算所述第一语句与所述第二语句的语义相似度。上述搜索处理方法包括:接收查询语句;根据所述查询语句获取至少一个搜索结果条目;通过上述通过计算机实现的语句相似度的计算方法,分别计算所述查询语句与所述搜索结果条目的语义相似度;根据计算的语义相似度的值对所述搜索结果条目进行排序;发送经过排序的搜索结果条目。本发明能够根据语句的语义计算出更准确的语句相似度,并提供更准确的搜索结果。

9.40.1.1.1. <u>http://www.soopat.com/Patent/201410722755?lx=FMSQ</u>
9.41. 恶意点击的防御方法和装置

9.41.1. 申请日:2015年01月26日

9.41.1.1. 本发明公开了一种恶意点击的防御方法和装置。该方法包括:获取推广内容对应的屏蔽策略;根据所述屏蔽策略和用户的历史点击信息,确定策略屏蔽列表中的待屏蔽用户;如果所述策略屏蔽列表中的待屏蔽用户进行检索,则将所述推广内容对所述待屏蔽用户进行屏蔽处理。本发明实施例的技术方案,在服务器前端进行推广内容展示的环节即实现了对恶意点击的阻止,一方面,可以基于实时的点击信息判定恶意点击,进行及时有效的防御,提高了防御的时效性;另一方面,屏蔽策略可以由商家用户进行设置,提高了商家用户对恶意点击控制的自主性。

9.41.1.1.1. <u>http://www.soopat.com/Patent/201510038602?lx=FMSQ</u>
9.42. 提取文档中关键词的方法及装置

9.42.1. 申请日:2015年08月19日
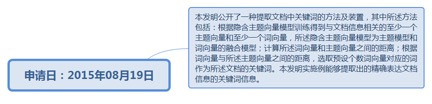
9.42.1.1. 本发明公开了一种提取文档中关键词的方法及装置,其中所述方法包括:根据隐含主题向量模型训练得到与文档信息相关的至少一个主题向量和至少一个词向量,所述隐含主题向量模型为主题模型和词向量的融合模型;计算所述词向量和主题向量之间的距离;根据词向量与所述主题向量之间的距离,选取预设个数词向量对应的词作为所述文档的关键词。本发明实施例能够提取出的精确表达文档信息的关键词信息。

9.42.1.1.1. <u>http://www.soopat.com/Patent/201510512363?lx=FMSQ</u>
9.43. 提取文档关键句的方法及装置

9.43.1. 申请日:2015年09月15日
9.43.1.1. 本发明公开了一种提取文档关键句的方法及装置,其中所述方法包括:根据层级语义向量模型训练得到与文档相关的句子向量和文档向量,所述层级语义向量模型包含预先根据文档训练资料库训练得到的句子向量更新公式和文档向量更新公式;计算所述句子向量和所述文档向量之间的相关性;选取所述相关性满足预设条件的句子向量对应的句子作为所述文档的第一关键句。本发明实施例能够提取出的精确表达文档信息的关键句。

9.43.1.1.1. <u>http://www.soopat.com/Patent/201510587652?lx=FMSQ</u>
9.44. 知识数据的处理方法和装置

9.44.1. 申请日:2015年09月30日
9.44.1.1. 本发明实施例公开了一种知识数据的处理方法和装置。所述处理方法包括:获取待检测的知识数据;从所述待检测的知识数据提取主体、谓词和客体的数据,得到相应的第一结构化知识数据;根据预设的知识冲突检测规则,将所述第一结构化知识数据和已有的第二结构化知识数据进行比对,确定所述待检测的知识数据是否与所述已有的知识数据存在信息冲突。采用本发明实施例,便于后续对存在信息冲突的知识数据的正确性做进一步判别,以提高知识库中知识数据的准确率。

9.44.1.1.1. <u>http://www.soopat.com/Patent/201510640181?lx=FMSQ</u>
9.45. 查询结果的底层召回方法和装置

9.45.1. 申请日:2016年05月11日

9.45.1.1. 本发明实施例公开了一种查询结果的底层召回方法和装置。查询结果的底层召回方法包括:根据搜索用户输入的目标查询式,从资源库中获取与目标查询式关联的查询资源;获取各查询资源的比对评分特征,其中,比对评分特征包括基础相关特征;将各查询资源的比对评分特征输入至预先训练的排序模型中,获取所述排序模型输出的,与各查询资源对应的相关性评分值,其中,排序模型为Gbrank模型;根据相关性评分值,对各查询资源进行排序,并根据排序结果选取设定数目的目标资源作为与目标查询式的底层召回结果。本发明的技术方案通过采用Gbrank排序模型,优化了传统查询结果的底层召回方法,提升了召回的目标资源与目标查询式的相关性。

9.45.1.1.1. <u>http://www.soopat.com/Patent/201610309835</u>
9.46. 基于深度问答的答案检索方法及装置

9.46.1. 申请日:2016年12月28日
9.46.1.1. 本发明提出了一种基于深度问答的答案检索方法及装置,其中,方法包括:接收输入的查询语句;根据查询语句检索得到包含候选答案的网页;基于网页分析方法、深度学习方法以及模板匹配方法分别获取第一候选答案、第二候选答案以及第三候选答案;根据第一候选答案、第二候选答案以及第三候选答案确定最终答案;展现最终答案。通过本发明能够在搜索结果页面中直接展示与用户查询问题对应的答案,提高答案检索的相关度和准确度,以及提高搜索结果的呈现效果。

9.46.1.1.1. <u>http://www.soopat.com/Patent/201611235007</u>
9.47. 用于识别网站的方法、装置及服务器

9.47.1. 申请日:2017年01月26日
9.47.1.1. 本申请公开了用于识别网站的方法、装置及服务器。该方法的一具体实施方式包括:获取待识别网站的网页集合;识别该网页集合中的异常网页,其中,该异常网页中的图片信息与文本信息的相关度小于相关度阈值;确定识别出的异常网页在该网页集合中的比率;根据所确定的比率,确定该待识别网站是否为垃圾网站。该实施方式提高了识别垃圾网站的效率。

9.47.1.1.1. <u>http://www.soopat.com/Patent/201710057271</u>
9.48. 基于人工智能的网页原创性识别方法、装置

9.48.1. 申请日:2017年03月11日
9.48.1.1. 本发明公开了基于人工智能的网页原创性识别方法、装置及存储介质,其中方法包括:分别对保存在数据库中的各网页进行句子提取;根据提取出的句子生成句子级的原创查找词典;根据原创查找词典,分别识别出从待识别的网页中提取出的各句子是否为原创句子;根据识别结果确定出待识别的网页的原创性。应用本发明所述方案,能够提高识别结果的准确性等。

9.48.1.1.1. <u>http://www.soopat.com/Patent/201710209215</u>
9.49. 基于人工智能的文章价值评估方法、装置及存储介质

9.49.1. 申请日:2017年06月06日
9.49.1.1. 本发明公开了基于人工智能的文章价值评估方法、装置及存储介质,可预先挖掘出作为训练数据的优质文章及劣质文章,并根据训练数据训练得到价值评分模型,这样,当需要对待评估的文章进行价值评估时,可首先对待评估的文章进行特征提取,进而根据提取出的特征以及价值评分模型,确定出待评估的文章的评分,从而实现了对于文章价值的有效评估。

9.49.1.1.1. <u>http://www.soopat.com/Patent/201710417749</u>
9.50. 基于人工智能的低质量文章识别方法及装置、设备及介质

9.50.1. 申请日:2017年06月20日

9.50.1.1. 本发明提供一种基于人工智能的低质量文章识别方法及装置、设备及介质。其方法包括:获取新闻推荐系统中的待识别的文章的用户反馈行为特征;根据待识别的文章的用户反馈行为特征和预先确定的低质量文章识别模型,识别待识别的文章是否为低质量的文章。本实施例的技术方案,能够根据待识别的文章的用户反馈行为特征和预先确定的低质量文章识别模型自动地对待识别的文章是否为低质量的文章进行识别,从而克服现有技术中人工审核待识别的文章是否为低质量的文章,费时费力且识别效率低的技术问题,不仅能够大大地节省对待识别的文章是否为低质量的文章进行识别的时间,还能够有效节省识别时消耗的人力成本,进而大大地提高对低质量文章的识别效率。

9.50.1.1.1. <u>http://www.soopat.com/Patent/201710469542</u>
9.51. 文本相似度的处理方法、装置、设备和计算机存储介质

9.51.1. 申请日:2017年09月18日

9.51.1.1. 本发明提供一种文本相似度的处理方法、装置、设备和计算机存储介质,其中所述文本相似度的处理方法包括:获取由多种相似度确定方法得到的文本对的相似度确定结果;将所述文本对的相似度确定结果进行拼接,得到拼接特征;将所述拼接特征作为相似度确定模型的输入,根据所述相似度确定模型的输出得到所述文本对的文本相似度;其中,所述相似度确定模型是预先训练得到的。通过本发明所提供的技术方案,能够实现对多种相似度确定方法所得到的相似度确定结果进行集成处理,并提高确定文本对的文本相似度的准确性,使得集成处理后的相似度计算准确性高于任何一种单一的相似度计算方式。
9.51.1.1.1. <u>http://www.soopat.com/Patent/201710841945</u>
9.52. 检索文本相关性的评估方法、装置、服务器和存储介质

9.52.1. 申请日:2017年12月07日

9.52.1.1. 本发明实施例公开了一种检索文本相关性的评估方法、装置、服务器和存储介质。其中,方法包括:对查询和检索文本组成的多个样本对进行文本特征提取,其中,所述文本特征包括原始文本特征和结构化文本特征;将所述文本特征和对所述多个样本对的相关性标注作为语料进行训练,得到评估模型,该评估模型用于评估查询与检索文本的相关性。本发明实施例实现了在评估检索文本相关性时兼顾评估问题的深入度与自动化,兼顾判决逻辑的准确性与泛化识别能力,能够通过评估提高检索召回的全面性和匹配度,提升用户体验,同时评估模型的训练与使用使评估文本覆盖量大,且降低了人工评估的成本。

9.52.1.1.1. <u>http://www.soopat.com/Patent/201711284320</u>
9.53. 标题生成方法、装置和电子设备

9.53.1. 申请日:2017年12月20日
9.53.1.1. 本发明公开了一种标题生成方法、装置和电子设备,其中,标题生成方法包括:获取待生成标题的文本,并将文本切分为多个分句;获取多个分句的特征信息;将特征信息输入至标题支撑句模型,以抽取出至少一个标题支撑句;将至少一个标题支撑句输入至标题生成模型,以生成对应的标题;基于标题打分模型对生成的标题进行打分,并根据标题的得分确定文本对应的标题。本发明实施例的标题生成方法、装置和电子设备,降低了人工成本,提高了效率和时效性,并且能够满足优化标题提高点击率的需求。

9.53.1.1.1. <u>http://www.soopat.com/Patent/201711384836</u>
9.54. 网站质量评估方法及装置
9.54.1. 申请日:2016年11月30日
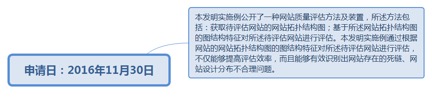
9.54.1.1. 本发明实施例公开了一种网站质量评估方法及装置,所述方法包括:获取待评估网站的网站拓扑结构图;基于所述网站拓扑结构图的图结构特征对所述待评估网站进行评估。本发明实施例通过根据网站的网站拓扑结构图的图结构特征对所述待评估网站进行评估,不仅能够提高评估效率,而且能够有效识别出网站存在的死链、网站设计分布不合理问题。

9.54.1.1.1. <u>http://www.soopat.com/Patent/201611082107</u>
9.55. 文本核心词识别方法和装置

9.55.1. 申请日:2017年01月19日
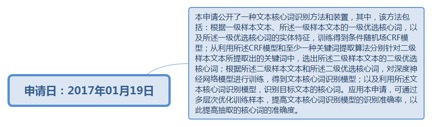
9.55.1.1. 本申请公开了一种文本核心词识别方法和装置,其中,该方法包括:根据一级样本文本、所述一级样本文本的一级优选核心词,以及所述一级优选核心词的实体特征,训练得到条件随机场CRF模型;从利用所述CRF模型和至少一种关键词提取算法分别针对二级样本文本所提取出的关键词中,选出所述二级样本文本的二级优选核心词;根据所述二级样本文本和所述二级优选核心词,对深度神经网络模型进行训练,得到文本核心词识别模型;以及利用所述文本核心词识别模型,识别目标文本的核心词。应用本申请,可通过多层次优化训练样本,提高文本核心词识别模型的识别准确率,以此提高抽取的核心词的准确度。

9.55.1.1.1. <u>http://www.soopat.com/Patent/201710044590</u>
9.56. 评论数据处理方法、装置及设备

9.56.1. 申请日:2018年04月10日
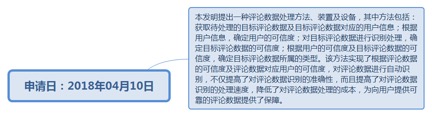
9.56.1.1. 本发明提出一种评论数据处理方法、装置及设备,其中方法包括:获取待处理的目标评论数据及目标评论数据对应的用户信息;根据用户信息,确定用户的可信度;对目标评论数据进行识别处理,确定目标评论数据的可信度;根据用户的可信度及目标评论数据的可信度,确定目标评论数据所属的类型。该方法实现了根据评论数据的可信度及评论数据对应用户的可信度,对评论数据进行自动识别,不仅提高了对评论数据识别的准确性,而且提高了对评论数据识别的处理速度,降低了对评论数据处理的成本,为向用户提供可靠的评论数据提供了保障。

9.56.1.1.1. <u>http://www.soopat.com/Patent/201810317233</u>
9.57. 文本作弊的识别方法及装置

9.57.1. 申请日:2018年04月28日
9.57.1.1. 本发明提出一种文本作弊的识别方法及装置,其中,文本作弊的识别方法包括:根据用户提交的当前文本和多个历史文本,提取得到多个嫌疑载体词;对所述多个嫌疑载体词进行载体识别,识别出最可疑的所述嫌疑载体词作为软文载体词;对所述当前文本和多个包含所述软文载体词的所述历史文本进行软文作弊识别,识别出所述当前文本是否为软文和/或所述用户是否为软文作弊用户。该文本作弊的识别方法及装置,由于基于多条语料(当前文本和多个历史文本)进行的软文作弊识别,即参考了用户的多个历史文本进行佐证,因此提高了软文识别率和识别精度。

9.57.1.1.1. <u>http://www.soopat.com/Patent/201810398470</u>
9.58. 页面正文提取方法和装置
9.58.1. 申请日:2018年06月01日

9.58.1.1. 本申请提出一种页面正文提取方法和装置,其中,方法包括:根据待处理页面的超文本标记语言代码,确定待处理页面对应的节点树,其中,节点树中的各节点分别为待处理页面中的各页面标签;根据预设的页面标签与权重值映射关系表,确定节点树中各节点对应的初始权重值;根据节点树中各节点间的关系及各节点对应的初始权重值,由末端子节点至根节点,依次更新各父节点的权重值;根据节点树中各节点更新后的权重值,确定待处理页面中的正文节点;根据正文节点,获取页面中的正文。该方法能够提升提取的页面正文的准确性,提升该页面提取方法的适用性,以及提升页面正文的提取效率。
9.58.1.1.1. <u>http://www.soopat.com/Patent/201810554392</u>
9.59. 对话内容连贯性的判断方法、装置以及设备

9.59.1. 申请日:2018年06月29日

9.59.1.1. 本发明提出一种对话内容连贯性的判断方法,包括:将上文语句输入至语句生成模型中,生成下文语句;计算每个上文语句与当前语句之间的相似度,以构建第一相似度矩阵;计算每个下文语句与当前语句之间的相似度,以构建第二相似度矩阵;将第一相似度矩阵和第二相似度矩阵分别输入至连贯性判别模型中,生成当前语句的连贯性特征参数,连贯性判别模型是基于卷积神经网络构建的。利用连贯性判别模型和语句生成模型相结合的方式,来解决对话内容连贯性问题,可以从语义的维度比对两个句子的连贯性,推送给用户回复连贯性且优质的回复。本发明还提供了一种对话内容连贯性的判断装置以及设备。

9.59.1.1.1. <u>http://www.soopat.com/Patent/201810694536</u>
9.60. 问题答案类型的确定方法、装置、设备及存储介质

9.60.1. 申请日:2018年06月29日

9.60.1.1. 本发明实施例公开了一种问题答案类型的确定方法、装置、设备及存储介质。该方法包括:提取输入的问答类查询语句的特征信息;将所述特征信息输入预先建立的序列标注模型和分类模型,得到所述序列标注模型输出的第一问题答案类型LAT结果和所述分类模型输出的第二LAT结果;根据第一LAT结果和第二LAT结果确定所述问答类查询语句对应的LAT结果。本发明实施例提供的问题答案类型的确定方法,利用序列标注模型和分类模型分别输出的LAT结果来确定问答类查询语句最终的LAT结果,可以提高确定LAT结果的准确性。

9.60.1.1.1. <u>http://www.soopat.com/Patent/201810695686</u>
9.61. 一种确定搜索结果的方法、装置、设备和计算机存储介质

9.61.1. 申请日:2018年06月08日

9.61.1.1. 本发明提供了一种确定搜索结果的方法、装置、设备和计算机存储介质,其中方法包括:获取当前搜索关键词query、当前query的历史query序列以及当前query的候选搜索结果;将所述当前query、当前query的历史query序列以及当前query的候选搜索结果输入搜索结果排序模型,依据所述搜索结果排序模型对所述候选搜索结果的评分,确定所述当前query对应的搜索结果;其中所述搜索结果排序模型对所述候选搜索结果的评分依据当前query和当前query的历史query序列的整合向量表示与所述候选搜索结果的向量表示之间的相似度确定。本发明能够向用户提供更准确体现用户需求的搜索结果。

9.61.1.1.1. <u>http://www.soopat.com/Patent/201810587495</u>
9.62. 搜索结果排序方法和装置
9.62.1. 申请日:2018年07月05日

9.62.1.1. 本发明实施例提出一种搜索结果排序方法和装置。该方法包括:从第一排序结果中获取用户请求和候选结果,用户请求中包括搜索问题,候选结果中包括候选问题和每个候选问题对应的候选答案;获取搜索问题与候选问题的第一相关性指标;获取搜索问题与候选答案的第二相关性指标;根据第一相关性指标和第二相关性指标,对第一排序结果进行重排序,得到第二排序结果。因为在第二排序中加入了更多特定的相关性指标,从而使排序结果不受单一排序方法的限定,可以更好更方便地提供精准的回答排序以及处理一些特定的问题。

9.62.1.1.1. <u>http://www.soopat.com/Patent/201810729232</u>
9.63. 一种网页重复的判断系统及其判断方法

9.63.1. 申请日:2011年01月28日
9.63.1.1. 本发明公开了一种网页重复的判断系统及其判断方法。该判断方法包括:获取多个网页;分别提取网页的网页正文;从网页正文中提取一个或多个句子,并根据一个或多个句子计算网页正文句子签名;根据网页正文句子签名对多个网页进行聚类;针对每一类下的网页,计算网页的附加签名;根据附加签名判断每一类下的网页是否重复。通过上述方式,本发明提供的网页重复的判断系统及其判断方法通过包括网页正文句子签名在内的多维度签名有效且快速地判断网页是否重复。

9.63.1.1.1. <u>http://www.soopat.com/Patent/201110031636</u>
9.64. 重复网页识别方法和装置
9.64.1. 申请日:2014年07月08日

9.64.1.1. 本发明实施例公开了一种重复网页识别方法和装置。所述重复网页识别方法包括:从互联网网页中识别至少一组原始重复网页,并将所述至少一组原始重复网页存储至重复网页集合;依据互联网网页的链接关系,从与所述至少一组原始重复网页有链接关系的网页中迭代的识别候选重复网页,并将所述候选重复网页存储至重复网页集合。本发明实施例公开的重复网页识别方法和装置利用互联网网页之间的相互链接关系提高了重复网页的识别效率。

9.64.1.1.1. <u>http://www.soopat.com/Patent/201410324553</u>
9.65. 一种应用的离线缓存方法和系统

9.65.1. 申请日:2017年11月15日
9.65.1.1. 本申请提供一种应用的离线缓存方法和系统,所述方法包括:从服务器获取应用的离线包;所述离线包包括:摘要文件、配置文件和离线资源文件;对所述离线包进行校验,利用校验通过的离线包更新缓存;当所述应用加载统一资源定位符URL时,查找所述摘要文件并进行校验,校验通过后,从缓存中查找获取与所述URL匹配的资源。可以实现离线缓存的及时更新,保证其完整性。

9.65.1.1.1. <u>http://www.soopat.com/Patent/201711128645</u>
9.66. 离线下载方法和离线下载服务器

9.66.1. 申请日:2013年05月02日
9.66.1.1. 本发明提出一种离线下载方法和离线下载服务器。其中该方法包括以下步骤:用户向离线下载服务器提交下载任务;离线下载服务器判断下载任务是否是已经下载过的任务;如果否,则根据下载任务判断下载方式;根据下载方式将与下载任务对应的资源下载到离线下载服务器;以及将资源拷贝到用户的空间。根据本发明实施例的离线下载方法,一方面免去了用户下载资源时需要挂机的烦恼,提升了用户体验,另一方面提升了用户下载资源的速度。

9.66.1.1.1. <u>http://www.soopat.com/Patent/201310158954</u>
9.67. 在线性页面结构下用于页面非线性跳转的方法和设备

9.67.1. 申请日:2014年07月18日

9.67.1.1. 本发明的目的是提供一种在线性页面结构下用于页面非线性跳转的方法与设备。处理设备获取并存储与一个或多个页面所对应的操作参数和/或数据参数;然后获取对所述一个或多个页面的页面访问请求;根据所述页面访问请求所对应的页面的参数信息,启动所述页面访问请求所对应的页面。与现有技术相比,本发明通过存储与页面相对应的参数信息,当再次访问该页面时,则直接调用所述参数以进行页面的访问,从而实现了在线性页面结构下进行页面的非线性跳转,避免了用户在进行页面跳转时的多次点击操作,使用户能够快速跳转,提高了用户的使用效率,改善了用户体验,同时由于保持了线性页面结构,因此不会影响系统后续对所述线性页面结构的调用。

9.67.1.1.1. <u>http://www.soopat.com/Patent/201410345839</u>
9.68. 视频选择播放方法、装置、设备和可读存储介质

9.68.1. 申请日:2019年07月16日

9.68.1.1. 本发明提供一种视频选择播放方法、装置、设备和可读存储介质,用户端在原始视频的播放界面中,显示原始视频对应的角色控件;根据用户对角色控件输入的操作,生成指示目标角色的查找请求;服务器从用户端获取的对原始视频的查找请求,根据查找请求在原始视频中,获取与目标角色对应的关键视频帧;根据与关键视频帧对应的关键场景特征,获取关键视频片段,其中,关键视频片段是包含至少一个关键视频帧且具有关键场景特征的连续视频帧;将指示关键视频片段的目标视频信息发给用户端;用户端根据目标视频信息,进行视频播放,从而使得用户可以通过简单的操作,在原始视频中对自己感兴趣角色的视频片段进行选择性播放,提高了用户体验。

9.68.1.1.1. <u>http://www.soopat.com/Patent/201910641968</u>
9.69. 文本表示方法、装置、设备和存储介质

9.69.1. 申请日:2019年06月11日

9.69.1.1. 本发明实施例提出一种文本表示方法、装置、设备和存储介质,其中的方法包括获取目标文本对应的多个词向量;从多个词向量中,获取目标文本的全局特征;根据全局特征生成多个全局信息,每个全局信息与至少一个词向量对应;根据多个词向量以及多个全局信息,获取目标文本的多个局部特征;根据多个局部特征生成目标文本的表示向量。本发明实施例的方法将文本的全局特征融合在局部特征的抽取过程中,因此生成的局部特征对于全局背景的理解会更好。进而,只需要很浅的网络就可以直接对文本进行分类,并取得优异的分类效果,并且无需额外的更深层的网络,以降低学习难度。

9.69.1.1.1. <u>http://www.soopat.com/Patent/201910504977</u>
9.70. 文本纠错方法及装置
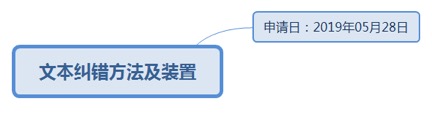
9.70.1. 申请日:2019年05月28日

9.70.1.1. 本申请提出一种文本纠错方法及装置,其中方法包括:将待纠错的文本对应的词向量数组输入预设的编码模块,获取第一隐状态向量数组并输入至解码模块,针对每个解码位置,根据该解码位置对应的第二隐状态向量、注意力向量和第一隐状态向量数组确定解码向量;根据解码位置的解码向量、全局性词表、以及解码位置的字词对应的受限词表,确定解码位置的解码结果,进而确定文本对应的纠错后文本,该方法中确定解码向量时,采用了第一隐状态向量数组,从而考虑到了文本的字词顺序,确保了纠错结果的准确度;另外,受限词表的采用,限制了解空间的大小,降低了纠错模型的复杂度,提升了模型收敛速度。

9.70.1.1.1. <u>http://www.soopat.com/Patent/201910452219</u>
9.71. 内容推送方法及装置
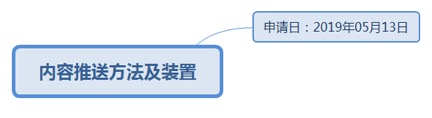
9.71.1. 申请日:2019年05月13日
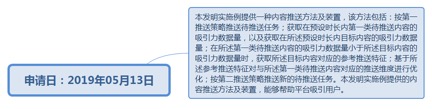
9.71.1.1. 本发明实施例提供一种内容推送方法及装置,该方法包括:按第一推送策略推送待推送任务;获取在预设时长内第一类待推送内容的吸引力数据量,以及获取在所述预设时长内目标内容的吸引力数据量;在所述第一类待推送内容的吸引力数据量小于所述目标内容的吸引力数据量时,获取所述目标内容对应的参考推送特征;基于所述参考推送特征对与所述第一类待推送内容对应的推送维度进行优化;按第二推送策略推送新的待推送任务。本发明实施例提供的内容推送方法及装置,能够帮助平台吸引用户。

9.71.1.1.1. <u>http://www.soopat.com/Patent/201910392924</u>
9.72. 文章判重处理方法、装置及电子设备

9.72.1. 申请日:2019年05月13日
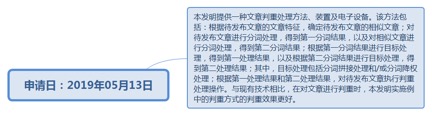
9.72.1.1. 本发明提供一种文章判重处理方法、装置及电子设备。该方法包括:根据待发布文章的文章特征,确定待发布文章的相似文章;对待发布文章进行分词处理,得到第一分词结果,以及对相似文章进行分词处理,得到第二分词结果;根据第一分词结果进行目标处理,得到第一处理结果,以及根据第二分词结果进行目标处理,得到第二处理结果;其中,目标处理包括分词拼接处理和/或分词降权处理;根据第一处理结果和第二处理结果,对待发布文章执行判重处理操作。与现有技术相比,在对文章进行判重时,本发明实施例中的判重方式的判重效果更好。

9.72.1.1.1. <u>http://www.soopat.com/Patent/201910394044</u>
9.73. 页面错误识别方法和装置
9.73.1. 申请日:2019年05月10日
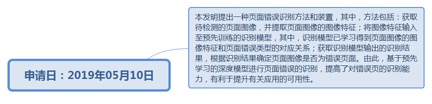
9.73.1.1. 本发明提出一种页面错误识别方法和装置,其中,方法包括:获取待检测的页面图像,并提取页面图像的图像特征;将图像特征输入至预先训练的识别模型,其中,识别模型已学习得到页面图像的图像特征和页面错误类型的对应关系;获取识别模型输出的识别结果,根据识别结果确定页面图像是否为错误页面。由此,基于预先学习的深度模型进行页面错误的识别,提高了对错误页的识别能力,有利于提升有关应用的可用性。

9.73.1.1.1. <u>http://www.soopat.com/Patent/201910389806</u>
更新: 2025-07-29 16:19:43
原文: <https://www.yuque.com/seoers/uyyd4f/ce3efi>